Title: Cosmological parameter estimation via iterative emulation of likelihoods
Authors: Marcos Pellejero-Ibañez, Raul E. Angulo, Giovanni Aricó, Matteo Zennaro, Sergio Contreras, Jens Stücker
First Author’s Institution: Donostia International Physics Center (DIPC), Donostia-San Sebastián, Spain
Status: Open access on arXiv
Say you want to make the perfect soufflé. You know how fluffy it should be, but you don’t know how many eggs and sticks of butter you need. You could try a whole bunch of different combinations, but this would take forever (and waste a lot of ingredients on bad soufflés). Your sous-chef decides to help you out: you tell them about some of your previous attempts and how the souffle turned out, and they build you a predictor. You can now tell the predictor any amount of eggs and butter, and it estimates how fluffy the soufflé will be!
This is the principle behind an emulator, which has become popular for estimating cosmological quantities. Today’s paper presents a new way of using emulators iteratively to perform this estimation even faster. This will get fairly technical, so put your apron on and prepare to get your hands dirty.
MCMC? More like MCM-See-ya-later!
Let’s translate cooking to cosmology. Now say you’ve measured a galaxy power spectrum (a.k.a. the soufflé) for the real universe, which describes the clustering of galaxies across scales. You want to figure out which cosmological parameters (a.k.a. the ingredients) produce this power spectrum. One way is to build a model that represents the universe, compute the power spectra for all possible sets of parameters, and see which one is closest to yours.
Alright, we can’t evaluate the model for all possible parameters, but maybe we could compute some subset of them. Here we usually turn to our good friend Markov Chain Monte Carlo, who goes by MCMC for short (for a visual explainer see here, and for a detailed explanation see this Astrobite). MCMC is basically a smart way of sampling the possible parameter sets for our model. At each parameter set, we evaluate the model and compute the likelihood that it fits our data—think of this as the difference between the model prediction and the truth. After lots of sampling, we end up with a sample that best represents the true distribution of possible parameter sets. This is the posterior distribution. The maximum of this distribution is our best guess for the parameters given our data.
However, for complex, many-parameter models it can be difficult to sample the parameter space adequately, and running MCMC for can become computationally prohibitive.
Emulation is the sincerest form of flattery
The reason standard MCMC is so expensive is that it requires a costly computation of the model at every step. This is where emulators come in: they can mimic the model in a speedy way. There are many ways to build an emulator (e.g. Gaussian Process emulators), but for our purposes we can think of it as a fancy interpolator.
The emulator takes in some training set of inputs (e.g. cosmological parameters) and associated outputs of the model (e.g. the power spectrum), which span the space of plausible cosmological parameters. The emulator learns the association between inputs and outputs; then for any set of cosmological parameters, it can predict the power spectrum.
Now that we have an emulator, we can compute each MCMC step faster, but we still need a lot of steps. The authors of today’s paper devise a method to iteratively build up a training set, using the emulator to select optimally located samples, to reduce the number of steps needed.
Round and round we emulate
The basic idea of iterative emulation is to choose your samples in a smarter way. It starts off with a normal emulator on a very small training set, and then carefully selects some new points to add to the training set. How does it choose which points? Using the likelihood distribution from the previous emulator (a.k.a. the distribution of all likelihoods evaluated so far). This makes sure that it better samples regions that it thinks are closer to the truth.
Here’s the recipe for the iterative emulation method:
- Generate a tiny training set, which sparsely covers the whole region of potential parameter space.
- Build an emulator for this training set. Evaluate the likelihood distribution given your data (it will be pretty wrong at first!).
- Now draw a few samples from your likelihood distribution, evaluate the model for these, and add them to your training set.
- With this expanded training set, rebuild the emulator. Evaluate the new likelihood.
- Iterate! (Repeat steps 3 and 4.)
- Know when to stop iterating by comparing the last two likelihood distributions. If they are very different, keep going; when they stay converged for a few iterations, stop.
- The last iteration of the likelihood distribution is your answer!
The process is demonstrated for a simple case in Figure 1, with the goal of estimating two parameters. The true value is at the center. At the first iteration (left panel), 5 points are chosen. The green shows the posterior after emulating at these points; you can see that it’s high (dark green) near the center point, and very low (white) near the other points. Going from left to right, the iterative method adds one point at a time (red), chosen from the previous likelihood. By the 4th iteration, the distribution is clearly centered on the truth. It also matches the standard MCMC run with 1000 evaluations (blue)—but the iterative method got there with only 9 evaluations.

Less (likelihood evaluations) is more
The authors give their approach a whirl on a more realistic problem: using the galaxy power spectrum to estimate a 9-parameter cosmological model. Starting off with a training set of only 10 power spectra, they apply their iterative emulation. The outcome is shown in Figure 2. The posterior distributions for their method are shown in green. They compare their results to a standard MCMC approach, shown in blue. Even in this 9-dimensional space, they recover very similar and accurate results, using—here’s the kicker—one hundred times fewer likelihood evaluations!
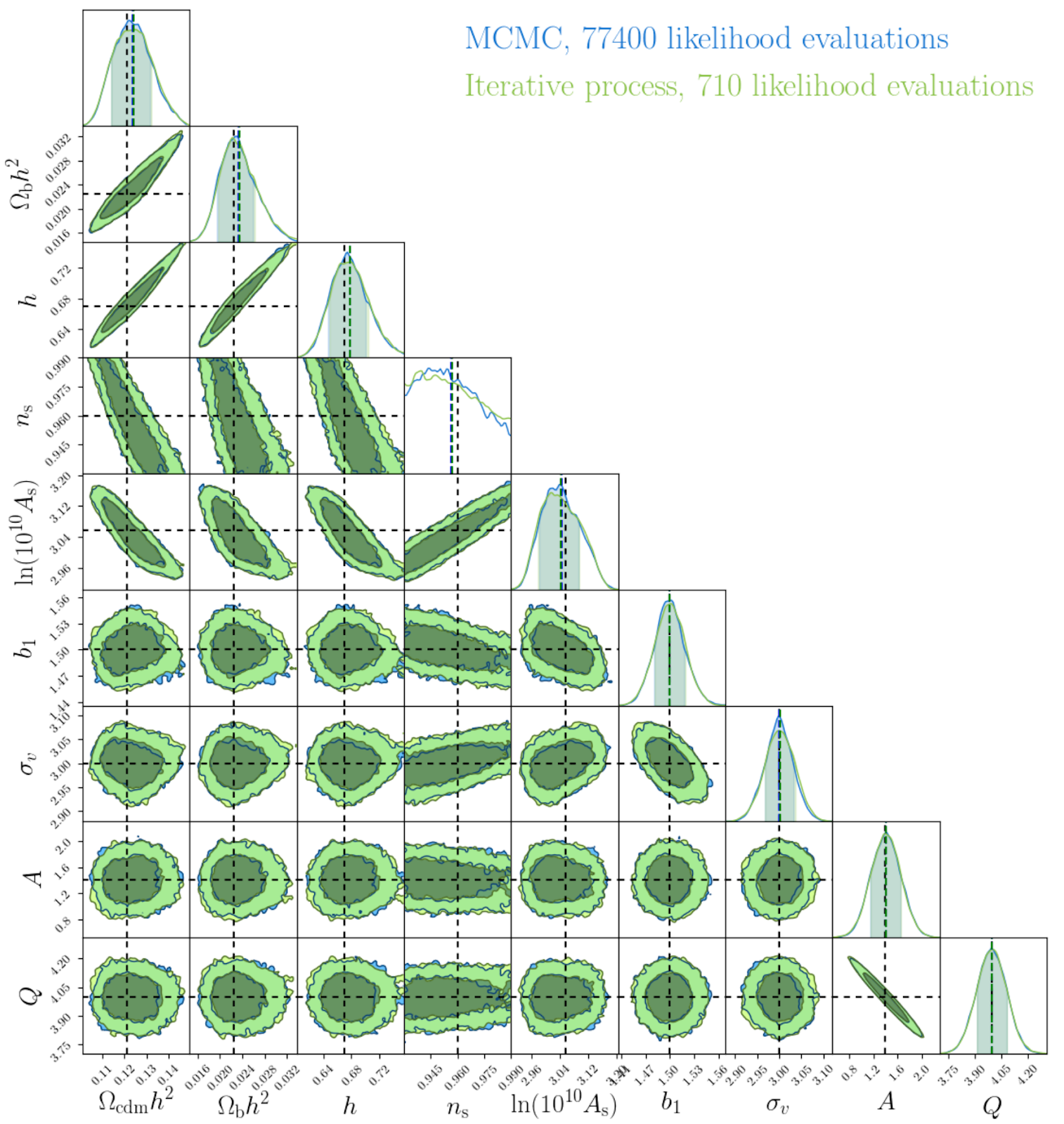
This approach results in a significant speedup in parameter estimation. This means we can efficiently sample more complex, higher-dimensional models that would be intractable with MCMC, resulting in more accurate estimates down the line. We’re sure that future research will try to emulate the clever work of this paper.

{kind=link}
Nice! Gonna check this method.
Thanks for writing!
That is a very interesting method! I will give it a try. Thanks a lot for the post.