Title: The ASAS-SN catalogue of variable stars I: The Serendipitous Survey
Authors: T. Jayasinghe, C. S. Kochanek , K. Z. Stanek, B. J. Shappee, T. W. -S. Holoien, Todd A. Thompson, J. L. Prieto, Subo Dong, M. Pawlak, J. V. Shields, G. Pojmanski, S. Otero, C. A. Britt, D. Will
First author’s institution: Ohio State University
Journal: Published in MNRAS; open access on arxiv
Since its creation in 2014, the All-Sky Automated Survey for Supernovae (ASAS-SN) has monitored the whole sky every 2-3 days down to ~17th magnitude. As this survey searches for supernovae, it often finds other variable stars too who are not exploding — yet their brightness, in general, varies with time! The authors of today’s paper attempt to classify ~90,000 variable star candidates found by ASAS-SN and present a catalogue of 66,179 previously unknown variable stars.
What’s the Data?
The data were taken with Brutus and Cassius (two of the six ASAS-SN units) between 2013-2017. Three 90 second images (later merged to increase the signal-to-noise ratio) were taken of each source in the sky in the V-band every 2-3 days. Data were processed using ISIS (an image subtraction software), photometry was performed using IRAF’s apphot package, and the images were finally calibrated using AAVSO’s Photometric All-Sky Survey (APASS). Sources were cross-referenced with existing variable star catalogues, and any variable stars that had already been discovered were removed from the sample. Finally the authors created a light curve for each candidate and used a variety of periodograms to find a period for each source.
What’s the Point?
The immediate goal of this project was to classify these ~90k variable star candidates, but the secondary goal was to be able to classify any new candidates that come in. Ideally, the authors would want to use a classification algorithm trained on ASAS-SN variable stars to achieve the second goal, as these classifiers are finely tuned to the data they’re trained on. To achieve both goals, the authors used an open-source random forest classifier called UPSILoN and visual review to create a catalogue of ASAS-SN variable stars. This catalogue was then used to train a new random forest classifier used to catalogue any new variable stars ASAS-SN might find.
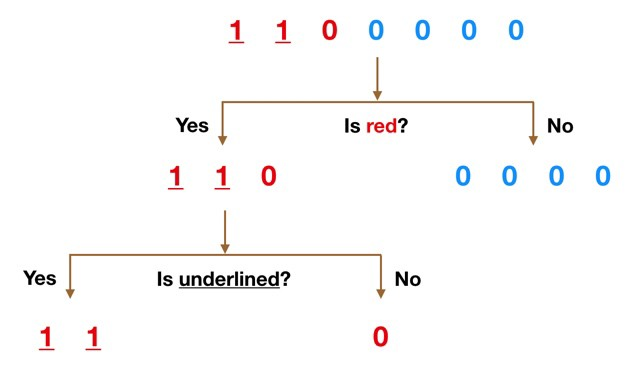
So What’s a Random Forest Classifier Anyway?
As the name suggests, it’s a classifier! It classifies using several decision trees (hence the ‘forest’ moniker) which are, essentially, a series of yes/no questions that the algorithm uses to split (or classify) the data. See Fig. 1 for an example! The special thing about random forest classifiers is that at each node, the number of features you can choose to split by is limited, and that subset of features is chosen randomly. This helps to keep the classifications from each tree uncorrelated. The data you need classified get sent through the forest, and the classification that is most common among the trees is what gets assigned.
Visual review of UPSILoN classifications was important because UPSILoN classifications didn’t quite match those of larger variable star catalogues, like VSX. During visual inspection, each source was labeled ‘variable/non irregular,’ ‘variable/irregular,’ or ‘bad.’ The ones labeled ‘variable/non irregular’ were often reclassified into (or out of) various subgroups of common variable star types, while those marked ‘variable/irregular’ were reclassified by their 2MASS and APASS magnitudes. Those marked ‘bad’ were often marked as such because of issues with photometry or astrometry and were removed from the data set.
Now the authors wanted to write their own classifier to train & use. Using scikit-learn, they built one and trained it on 80% of the UPSILoN + visual data set & tested it on the remaining 20%. Once the forest parameters were fine tuned and 16 variable class features were chosen to separate the data, the new classifier was retested on the complete set of data and was used to classify ~6,000 sources UPSILoN possibly misclassified & ~4,000 new sources found in the interim.
What’s in the Catalogue?
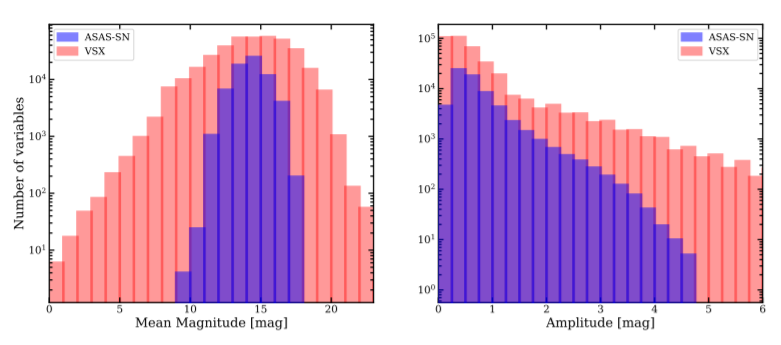
The final catalogue is composed of 66,179 newly discovered variable stars. These stars are well sampled over the sky (as ASAS-SN is an all-sky survey) and most have high-amplitude variability, as this variability resembles that of a supernova. The average variable star in the catalogue has a mean magnitude of V ~ 14.3 and a mean variability amplitude of A ~ 0.69 mag. Shown in Fig. 2, fainter variables tend to have higher amplitude. This makes sense because brighter variables with large amplitudes are likely to have been caught by other surveys. Additionally, stars in this catalogue are fainter than those already found; this is expected for similar reasoning. This catalogue was able to increase the number of known variables with magnitudes 13 < V < 16 by ~30%!
Overall the new classifier did pretty great! It had precision (true positives over all positives) and recall (true positives over all relevant elements) values of 89% and 85%, respectively. The most important features the classifier could recover were the period and color. These descriptors are crucial in classifying variable stars as they define the classifications themselves & can be used in determining other features, such as the luminosity. There’s an estimated classification error of ~ 10% with most of the uncertainty coming from confusion between subgroups of the main variable star types (specifically those of the eclipsing binaries). The classifier, although trained on ASAS-SN data, can be easily adapted (by retraining on new data sets) for use at other observatories focused on transient research, such as the Vera C. Rubin Observatory (previously known as LSST). Today’s paper was the first of 6(+) in the series. The second paper goes into detail about how the authors used their new classifier on the entire VSX catalogue!