Title: A Novel Machine Approach to Disentangle Multi-Temperature Regions in Galaxy Clusters
Authors: Carter L. Rhea, Julie Hlavacek-Larrondo, Laurence Perreault-Levasseur, Marie-Lou Gendron-Marsolais and Ralph Kraft
First Author’s Institution: Département de Physique, Université de Montréal, Québec, Canada
Status: Accepted to AJ, open access on arXiv
Galaxy clusters are among the largest gravitationally bound structures in the Universe. One of their defining characteristics is that they tend to be embedded within a large reservoir of superheated gas, known as the intracluster medium (ICM). With temperatures up to 108 Kelvin, the ICM is a strong emitter of X-ray radiation. The resulting spectra is dominated by thermal bremßtrahlung radiation: radiation emitted when charged particles are decelerated. Characterising this thermal emission provides useful insights into the physical processes within the cluster, such as galaxy merging and AGN activity, as well as various physical parameters including temperature and metallicity. In order to obtain these parameters, one must first fit the observed spectra. However, the ICM is not necessarily uniform. Different regions are often characterised by multiple thermal components, hence requiring a mix of temperatures rather than a single temperature model to reproduce the observed spectra. The authors of today’s bite propose a new machine learning (ML) method to systematically estimate the different underlying thermal components in ICM spectra. As this approach is not reliant on any particular physical model, it is both efficient and portable.
The Component and The Forest
The authors’ machine learning approach features two key techniques; principal component analysis (PCA) and random forests. The idea of PCA is to break large, multi-dimensional datasets into their principal components (amo, amare, amavi, amatum); these are a series of orthonormal basis vectors such that each vector points in a direction of maximal variance. This is analogous to solving for eigenvectors, and the data processing can be thought of as a change of basis. PCA is extremely useful for machine learning because it structures the data in a way that best highlights relevant features (while discarding those that are redundant/irrelevant). This improves the learning capability and efficiency of ML techniques. The authors use a random forest of decision tree classifiers to classify the processed data (i.e. the data after having been transformed via PCA). In a decision tree, the dataset is recursively partitioned until each subset corresponds to a specific class or category. Since decision trees are quite unwieldy and prone to overfitting, it is often beneficial to train several thousand at once (i.e. a random forest). Given an input corresponding to a region of X-ray emission, the goal is to output the number of unique thermal components. The authors create the training data using synthetic X-ray spectra based on observations taken from the Chandra observatory.
The King of Mycenae
The authors applied their ML method to the Perseus cluster, which is known to have regions with multiple temperature components. Figure 1 shows that the overwhelming majority of the Perseus cluster consists of a two-component thermal emission (blue), with some regions of four-component (yellow) and single-component (indigo) emission. This verifies previous conclusions, based on Chandra observations, that the Perseus cluster cannot be accurately modelled with a single temperature component.
Mapping the Components
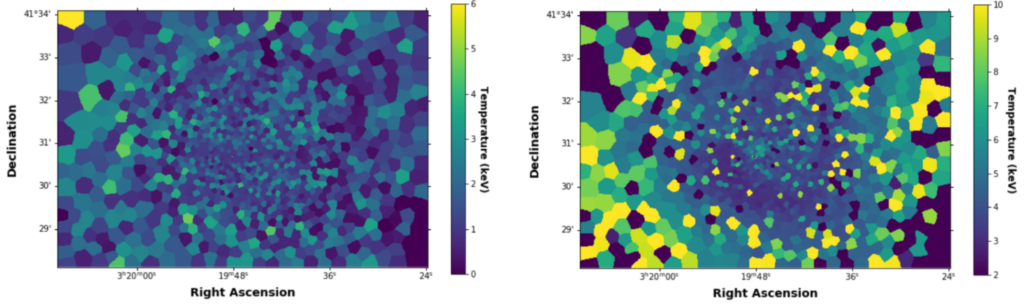
Having established that there are two main temperature components, the authors next calculated temperature maps. Figure 2 shows each of these components. Overall, each component corresponds to gases at different temperatures; the first component is characterised by a relatively cooler gas (of around 2 keV), while the second corresponds to a hotter gas (of 4 keV). These also correspond to soft and hard X-ray emission. What is encouraging is that these components are distributed differently: the cool gas is mostly uniform while the hot gas is more uneven. Some regions with a low first-component temperature have a high second-component temperature (and vice versa). Thus only by combining these different components can one accurately model the thermal nature of X-ray emission throughout the ICM.
Onwards and Upwards
One of the major benefits of this ML approach is that it is not solely restricted to Chandra data; it can be used with other X-ray missions such as Athena and eROSITA. The authors expect that future, high resolution surveys will result in improved classifications. This is since the random forest classification is sensitive to many factors including resolution, time epochs (since CCDs degrade over time), along with selection biases in the choice of training data (e.g. redshift, column densities). The authors have demonstrated that a new machine learning technique is capable of extracting the multiple thermal components in ICM X-ray emission, confirming that the Perseus cluster is indeed best characterised by more than one component. As future surveys yield stronger constraints on ICM emission, it will be possible to model physical processes in greater detail, ultimately improving our understanding of galaxy clusters and the evolution of galaxies contained within.