Programming is the bread and butter for most researchers in modern science, and involves anything from writing small scripts to workflows with many interacting parts. However, most of us are self-taught programmers, without proper training in best practices for code development. It’s likely that you’ve come across notoriously messy “monster codes”, with unclear documentation and mangled coding that make them a nightmare to work with. While the practice of properly documenting and reviewing collaborative coding projects is improving, research code or software that is not collaborative rarely sees the eye of anyone apart from the person who writes it, and hence is usually neither tested nor documented rigorously, nor publicly shared.
Research codes must be accessible for other scientists to reproduce and build upon studies. Modern scientific research can certainly benefit from adopting certain best-practices from the software industry for making software usable, maintainable and available. In today’s bite, we will look at some of these key practices for writing good code.
Why is cleaner code important?
There are various reasons why we would like to adopt software engineering practices that make our research code more robust and accessible:
- We will be helping our future selves and others. I am sure my experience of struggling to decipher a code I wrote even half a year ago is not unique. Moreover, making code accessible and sharing it publicly will encourage others to use it and not waste their time reinventing the wheel for each new application.
- We will be organizing and speeding up our research, which will save us countless hours of debugging and frustration.
- We will develop useful skills for prospective jobs outside academia, such as in the data science and software industries, which have absorbed quite a few astronomy graduates in recent years.
Software Engineering 101
There are four commonly understood principles of software engineering that define “good code”:
1. Modularity: Making a code modular simply means dividing it into small functional units or refactoring it (changing the structure of the code without changing what it does). This is done in accordance to the Do-not Repeat Yourself principle, which usually takes the form of converting commonly used pieces of code into functions or classes whenever possible, instead of copy-pasting them every time there’s a need. A modular code has three main benefits:
- It’s much more human readable
- The code can be fixed easily when it breaks (otherwise we will have to make the corrections to every copy of the code)
- The code can be easily taken to another project.
Figure 1 illustrates a simple example of refactoring a function in Python.

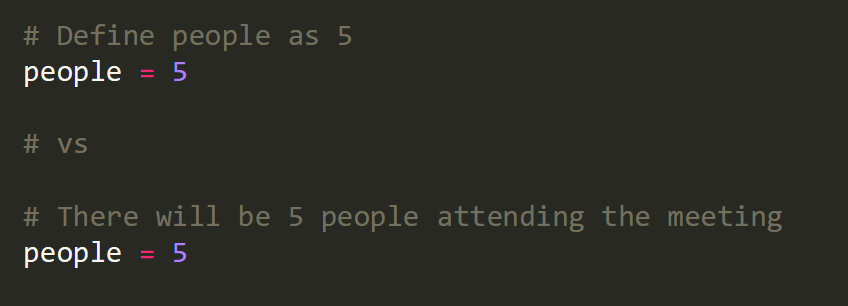
2. Documentation: Documenting our code can help prevent confusion from our collaborators and frustration from our future-selves. A well documented code clearly shows users what each section of the code is trying to accomplish, in the form of comments (and docstrings in case of Python) and separate README files. For comments, the rule of thumb is that the comment should explain why a piece of code is doing what it does, instead of what (see Figure 2 for an example). Secondly, creating documentation of your code (in the form of a document or a website) is a great practice to make it more accessible for others. This is what we would like a new user to look at first, instead of directly having them dive into the code. Good documentation covers three important aspects:
- The purpose of the code – what does one use it for?
- The installation process – how does one get the code set up and working on their computer?
- The usage – how to use the code? This is usually demonstrated through examples.
Here’s a great example of a documentation website, for the astronomy software “contaminante”.
3. Testing: Testing involves writing unit tests for individual functions to test (Python example) and validate that each individual part of our code performs as expected. Testing our code is especially important in science as the code might run fine but end up with wrong insights and recommendations due to values encoded incorrectly, features being used inappropriately, or the data breaking assumptions that the models are actually based on. Unit tests can also be the starting point of writing a piece of code, which is known as test driven development (TDD). While the usual workflow most of us would follow would be to first code the logic and then test it, TDD turns this process completely around. Rather counterintuitively, we start our code by writing the unit tests and a skeleton of the main logic (Python example). The tests are bound to fail at the start, but then we slowly fill in the gaps until the tests pass. Finally, to save us the trouble of remembering to run our tests each time we make a change to our code, there are automated services, like TravisCI, that monitor an online repository of the code (for example, hosted on GitHub) for changes and run the tests whenever a change is made.
4. Version control: The struggle to keep track of multiple versions of a file, whether it’s a script of code or a manuscript, is not uncommon in academia. A version control system, like git, not only provides an organized way to track changes and revisit older versions of our files, but can also allow multiple users to make changes to the same files, while keeping track of all changes. (It’s usually the lack of a version control system that leads to the “monster” codes.) GitHub is an online hosting platform for git repositories, which makes it easy for people to share their code with the rest of the world. GitHub also provides private repositories, so we can share our code and invite inputs from specific people. A private repository can also serve as a backup system for our research code (I use this for all my code!). Although private repositories are a paid feature in GitHub, academic accounts get free access to this feature!
Personally, I have found that an easy way to force myself to follow these good practices is to make it a goal to publish the code related to any research project, or at least share it with a few other people. Not only does this contribute to increased transparency and reproducibility on my part, but I am also motivated to present the best possible version of the code! If my attempt at illustrating good coding practices was too technical, perhaps the Zen of Python will convey the essence of what I have discussed here. If you are not already doing so, I hope this article motivates you to apply these coding practices to your projects. Happy coding!
Here are some resources:
- Get your code peer-reviewed and published in The Journal of Open Source Software!
- Google style guide for various languages
- Software Carpentry (a non-profit that teaches researchers computing skills)
- AGU-2018 workshop on Open Source Software
- Software engineering fundamentals for Data Scientists
- SciCoder (periodic workshops to introduce early-career researchers to modern programming practices)
- Sphinx (generate beautiful documentation)
- Travis CI (continuously test your code)
- GitHub (host your projects with git)
- Codecov (discover where to improve your project tests)
- Code Climate (analyze your code for improvements in readability)
Astrobite edited by: Briley Lewis
Featured image credit: https://astronomy.osu.edu/undergraduates/courses/nonmajors/astronomy-1221
Very solid and insightful post. Thank you for sharing!