Authors: R. Cañameras, S. Schuldt, S. H. Suyu, S. Taubenberger, T. Meinhardt, L. Leal-Taixé, C. Lemon, K. Rojas, E. Savary
First Author’s Institution: Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Str. 1,85748 Garching, Germany
Status: Submitted to Astronomy and Astrophysics [closed access]
One of the most pressing concerns of modern cosmology is the value of the notorious Hubble constant, H0, which defines the rate of expansion of the universe. Just as you might feel tense with the state of the world right now, there is an ongoing tension between measurements of this constant, which is an important constraint for the evolution of the universe. Luckily for us, various probes exist to help us better constrain H0. One of these is measuring the time delay of strongly lensed supernovae.
Nature’s Telescopes
Stop reading and go take a look at a light source like a candle through the bottom of a wine glass (or page 6 of this handy visual). You’ll see that the image of the candle is magnified and distorted by the wine glass in a ring. You’ll also see the image multiple times, depending on how far away you hold the candle or the shape of your glass. This is akin to what we see in a gravitationally lensed system. General relativity predicts that light follows the curvature of spacetime imposed by massive objects in the universe. If we have a very massive galaxy or cluster (our lens/“cosmic wine glass”), light from objects behind it, which must whiz toward us at a constant 300,000 km/s, has to take a detour around the lens, with each path having a slightly different length. This causes our telescopes to see multiple images of the lensed source at different times, which can be directly measured if the object being lensed is time-varying, such as a supernova. Since these time variations are based on cosmic distances, they are dependent upon cosmology, and from geometric relations we can derive H0.
Lensing is a useful tool for probing the structure of dark matter and high redshift galaxies, but it can also help us decide when to do follow up observations of transients and give insight into the problem of supernova progenitors and stellar evolution. But in order for astronomers to leverage lensed systems, they first must find them in the vast sea of galaxies. Instead of manually searching for these needles in our cosmic haystack, the authors of this paper decided to see if they can make computers play the “I spy with my little eye” game using neural networks.
Oh Lenses, Where Art Thou?
The authors aimed to find wide-separation strong lenses (systems that yield images that are multiple arcminutes apart) in the PAN-STARRS 3π survey. Wide separation systems have longer time delays than smaller ones, which are more conducive to finding and monitoring multiply imaged supernovae. Specifically, they wanted to find high redshift galaxies that are being lensed by large Luminous Red Galaxies (LRGs). This gave them a better chance of finding multiply-lensed images with worse (>1’’) seeing by being good at separating foreground emission from background emission. Since there are A LOT of galaxies in the 3π survey (~3 billion!), it would be inefficient to spend an enormous amount of computing power to run every single one through a neural network. Therefore, the authors decided to use a two-step method in hunting down these lensed systems. First, they created a set of mock lenses by painting real lensed sources from the COSMOS survey onto cutouts of PAN-STARRS LRGs (especially in the field of gravitational lensing, there are simply not enough discovered lenses for a neural network to learn from, creating the need for fake data). They also included some real objects that are not lenses, such as interacting galaxies, in their training sample.

Their second step was to use a simple neural network to find all the galaxies in the survey that had similar colors and magnitudes to the mock set. Then, they took this sample of photometrically-similar galaxies and classified their image cutouts as a lens or non-lens using a convolutional neural network (CNN). Before we see what they discovered, let’s demystify what exactly a neural network is and how it works.
If I Only Had a (Human) Brain!
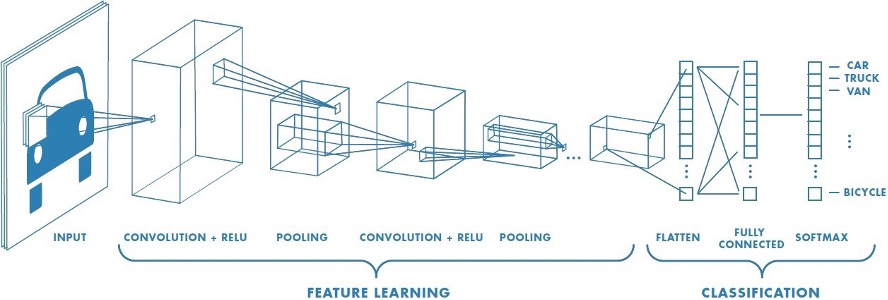
Our brains are great at finding patterns around us to identify objects and tell us that “this is a poodle” and “here is a tabby”. But while we can see a dog or a cat, a computer just sees an array of numbers (whether they be photometric properties or pixel values). Scientists have taken inspiration from the structure of our own cranium to create artificial neural networks: layers of artificial neurons with different weights and biases that are connected to each other like our own synapses, where each layer’s output becomes input for the next layer. The neurons take a subset of our number grids (training data) and process this input signal, propagating it through each of the layers to output a prediction of whether or not the input received is a lens or non-lens. It then calculates the difference between its predictions and the true labels of the data and uses this information to play around with the weights and biases of each neuron to improve its model, ending with a set of final labels. Convolutional neural networks function in the same way, but they are better at classifying images because they are inspired by our visual cortex.
HOLISMOKES — There They Are!
After training a neural network on mock photometric data, the authors identified around 1 million PAN-STARRS galaxies which got a high enough score to indicate that they were consistent with the mock data, in terms of their colour and magnitude. They then trained a CNN using images of the mock data to achieve a lens-finding accuracy of 95.5%. Next, they ran their PAN-STARRS subset through this network, manually inspecting galaxies that the CNN assigned high scores to, giving each galaxy a final score representative of how likely it is to be a lens. They ended up discovering 330 new lensing candidates and recovering 23 known ones!

The authors hope that their two-step classification system will be invaluable for the upcoming Rubin Observatory, which is expected to produce 20 terabytes of data per night! With data pumping out at astronomically high rates, it is no wonder that astronomers are looking for ways of automatically combing through it to help us find the next exciting supernova or constrain our estimates for Hubble’s constant.
Astrobite edited by Katy Proctor & Bryanne McDonough
Featured image credit: R. Cañameras et al.