Title: An Algorithm for Reconstructing the Orphan Stream Progenitor with MilkyWay@home Volunteer Computing
Authors: Siddhartha Shelton, Heidi Jo Newberg, Jake Weiss, Jacob S. Bauer, Matthew Arsenault, Larry Widrow, Clayton Rayment, Travis Desell, Roland Judd, Malik Magdon-Ismail, Eric Mendelsohn, Matthew Newby, Colin Rice, Boleslaw K. Szymanski, Jeffery M. Thompson, Carlos Varela, Benjamin Willett, Steve Ulin, and Lee Newberg
First Author’s Institution: Rensselaer Polytechnic Institute
Status: available on Arxiv, planned submission to ApJS
When I was fourteen, I read the Three-Body Problem and was fascinated by its description of alien civilizations. Although there were no astronomy classes offered in my middle school in China, I found SETI@home on the Internet and watched in amazement as my laptop calculated away, searching for extraterrestrial radio signals. SETI@home connects many idle computers through the Internet into one supercomputer for research use. Today’s paper is a pilot test for a similar distributed computing project on MilkyWay@Home.
This project aims to measure how much dark matter dwarf galaxies contain. The immense gravity from our Milky Way galaxy can rip apart dwarf galaxies and stretch their stars into long thin streams. From the distribution of stars in currently observed streams, astronomers can backtrack the properties of the progenitor dwarf galaxy before it was disrupted (see this astrobite for previous modeling efforts). Dark matter is invisible except through its gravity, so researchers observe the motion of stars and model the gravitational effects of dark matter.
The Algorithm
The algorithm tested in today’s paper models stellar streams with a range of input dwarf galaxy parameters and finds the best fit to the observed stellar stream. This model requires the complete 6-dimensional spatial and velocity information of the stream, which is now available thanks to the Gaia space telescope. The program also takes input parameters of the progenitor dwarf galaxy: its baryonic mass and size, and the ratio from baryonic to dark matter mass and size. An additional parameter describes the duration of the fall of the dwarf galaxy into the Milky Way, and the orbit of the observed stream is rewinded by this amount of time to recover an initial position. From this position, the dwarf galaxy is released into a fixed Milky Way potential. Each star and dark matter particle in the dwarf galaxy experiences the combined gravitational force from the Milky Way potential and all the other particles. An N-body integrator calculates the gravitational force and determines the orbit of each particle.
The tidal field of the Milky Way disrupts the dwarf galaxy and strips some of the stars off into a stream along its orbit. The program compares the modeled stream to observational data in terms of its density distribution, mass, and width. The researchers define a likelihood function based on these comparisons and vary the input parameters until the maximum likelihood is reached. This approach requires 50,000 simulations before settling on an optimized value, so it is computationally intensive. On a typical laptop, one optimization with this program could take hundreds of years to complete. That is too long for any researcher to wait and supercomputers are very useful for such kinds of problems.
Distributed computing
Distributed computing is one way to “build your own supercomputer” and enormously boost the computation speed if enough volunteers contribute their CPUs.
The research team in today’s paper recruited hundreds of thousands of volunteers like me running the program on their idle computers. With 800 TeraFLOPS of aggregated computing power, a calculation that needs to run for three days on a typical laptop can be done in one second on this network. With this technology, they successfully recovered the best fit to the observed stream.
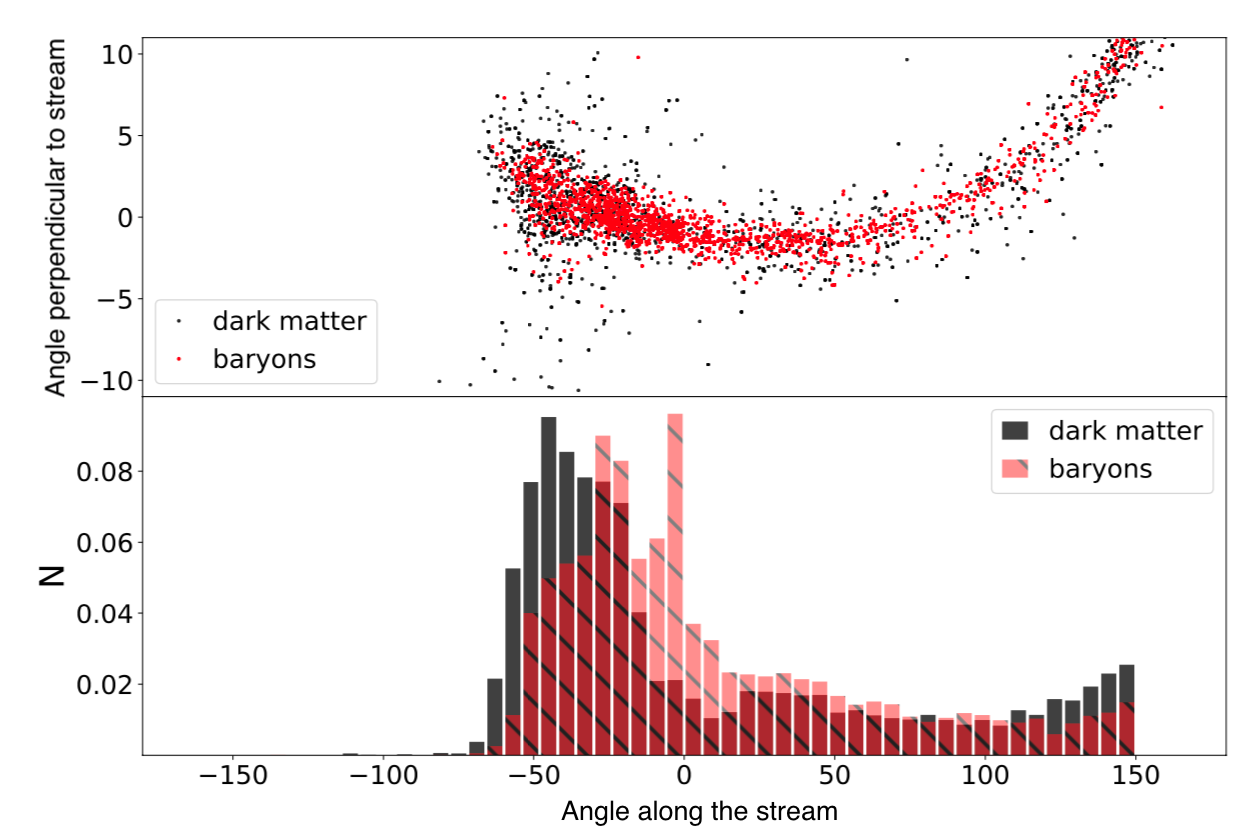
Figure 1. Top: Positions of particles in the simulated stellar stream. Bottom: Histogram of particle density along the stream. The dark matter and baryons have similar density distributions, while the main difference is the baryonic core at angle ~0 along the stream. Only the baryon density is used for model fitting. Reproduced from figure 3 in the paper.
Results
As the first test, the authors generated a stellar stream knowing the progenitor dwarf galaxy, the orbit of the stream, and the dark matter distribution (see Fig 1). Then, they observed a fake stream by hiding unobservable dark matter information and keeping the 6-dimensional spatial and velocity of stars. With only the observable quantities as input, the fitting algorithm recovered the input parameters including the dark matter mass.
In the future, the authors plan to expand the algorithm to simultaneously fit the dwarf galaxy with its orbit, a more physical dwarf galaxy progenitor model, and the Milky Way parameters. They hope that simultaneous fitting of multiple tidal streams will constrain the parameters of the Milky Way and will include the effects of Milky Way satellite galaxies like the Large and Small Magellanic Clouds.
This paper shows a promising new avenue to model stellar streams. Future research may use this modeling tool to recover the dark matter mass of dwarf galaxies and compare them to the predictions of dark matter theory. Not only does distributed computing help researchers who do not have full access to a supercomputer, but also inspires science enthusiasts to become future scientists as it inspired me.
Astrobite edited by Sabina Sagynbayeva
Featured image credit: Zili Shen