
Torsha Majumder
University of Lethbridge
I am a Data Scientist turned Astronomer! I am currently pursuing my M.Sc. degree at the University of Lethbridge and hold a master’s degree in computer science from the University of Texas at Dallas. My research interests primarily lie in anomaly detection in transients and double Fourier interferometry. Besides research, I am equally passionate about instrumental music, sketching, and photography. I am also an aspiring Astro-photographer.
Machine learning is a pivotal tool in modern astronomy. Its diverse applications are attributed to the ability to develop algorithms that can learn and adapt from data, thus providing a robust and reliable solution to complex problems. Implementing machine learning in astronomy has revolutionized the field, enabling significant breakthroughs in various scientific endeavors. Its use is prevalent in citizen science projects for data analysis, classification tasks, and anomaly detection in spacecraft telemetry.
Survey telescopes like the Zwicky Transient Facility, The Dark Energy Survey, the All-Sky Automated Survey for Supernovae, and The Panoramic Survey Telescope and Rapid Response System produce petabytes of data. At the same time, the Vera C. Rubin Observatory captures 20 terabytes of images every night. These large datasets contain rare and unknown astronomical events known as anomalies. In the field of transient astronomy, anomaly classes such as kilonovae, tidal disruption events, intermediate luminosity transients, pair-instability supernovae, active galactic nuclei, gamma-ray bursts, and superluminous supernovae type-I and type-II are considered distinct and rare (as opposed to more common supernova classes). Detecting anomalies is also crucial in discovering exoplanets, as it involves scrutinizing atypical transits in the light curves of stars. The extensive telescopic data also contains irrelevant information, such as instrumental artifacts or noise, which may interest a systems design engineer more than an astronomer. Therefore, these astronomical sources are considered anomalies based on the specific interests of a scientist.
Annotating and categorizing extensive telescopic data poses a significant challenge for human experts. The annotated data consists of labeled information pertaining to astronomical phenomena, facilitating the development of machine-learning models for discerning data patterns. These models can subsequently be employed for classification purposes. This class of algorithms is commonly recognized as supervised learning, as it prioritizes the construction of models guided by known labels. By juxtaposing the model’s predictions against the actual labels, the algorithm can acquire the ability to accurately classify new data. This methodology has demonstrated considerable efficacy across diverse domains, encompassing image and speech recognition, natural language processing, fraud detection, exoplanet discovery, and anomaly detection in astronomy.
The utilization of citizen science projects involves the application of traditional crowdsourcing methods to harness human insight for the purpose of labeling astronomical data. This involves providing simple yes/no answers to patterns observed in images or light curves presented in the form of questions. The collective aggregation of information within a group often leads to superior decision-making compared to any individual member within that group. This approach is rooted in the successful concept known as “The Wisdom of Crowds” as proposed by James Surowiecki. Citizen science projects play a crucial role in annotating data, which is vital for supervised learning and the validation of machine learning systems. By introducing these data to a larger group of human volunteers, these projects have broadened the scope of classification tasks. The classifications made by the volunteers undergo a rigorous inspection by a small science team. Notable citizen science space projects include Galaxy Zoo 3D, Planet Hunters TESS, Disk Detective, Kilonova Seekers, and others. Additional projects can be explored on Zooniverse and SciStarter.
Nonetheless, annotating substantial data volumes poses notable challenges, particularly when managing information at the terabyte scale. While crowdsourcing through citizen science projects can yield benefits, it is time-intensive. However, unsupervised classification and active learning can help address these challenges.
Unsupervised classification involves training a classifier without the need for annotated data. These algorithms learn directly from the data by transforming it into a new feature space, often referred to as latent space. The goal of unsupervised learning is to cluster these features into known events, instrumental artifacts/noise, and unknown events, as illustrated in Figure 1. Classical machine learning algorithms used in unsupervised classification include Hierarchical Density-Based Spatial Clustering and Isolation Forest. An intriguing application of unsupervised learning is anomaly detection in astronomy. These techniques aim to identify interesting anomalies from a pool of anomalies labeled as rare or new events. However, this category of algorithms lacks a quantitative measure of effectiveness and accuracy, making it difficult for humans to interpret the results.
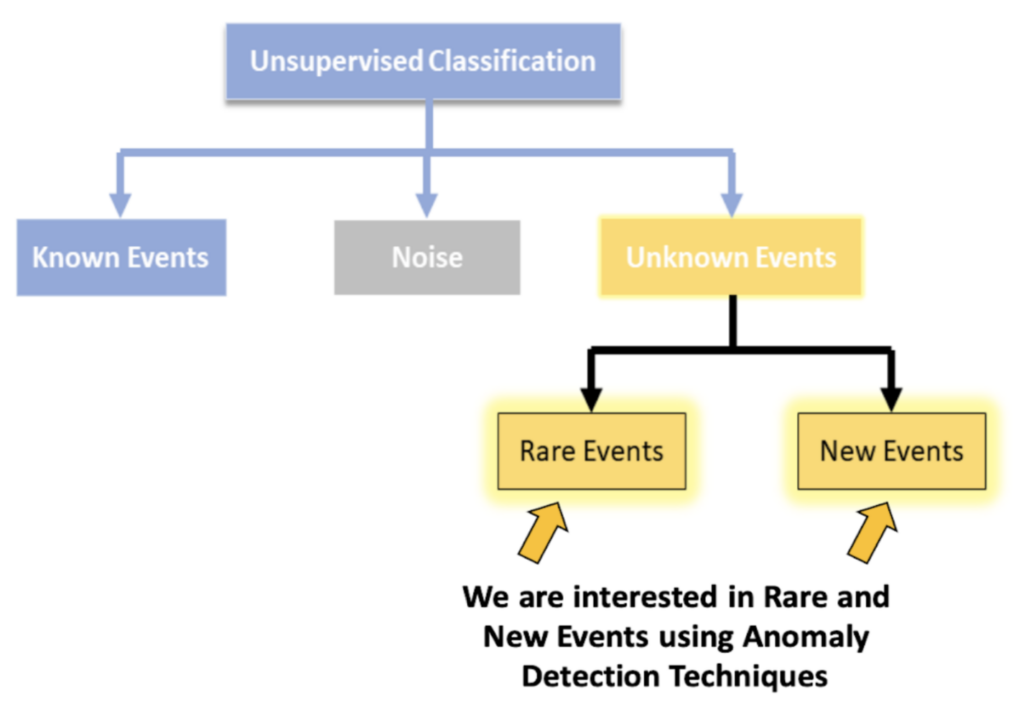
Unsupervised learning encounters challenges in distinguishing interesting anomalies from irrelevant data, including instrumental artifacts or rare astronomical sources that hold no interest for a specific scientist. While machine learning algorithms show promise for anomaly detection, there is a need for a classifier with the sensitivity to detect domain-specific anomalies in real-time, such as those related to transient and exoplanet discoveries. Advanced research in active learning has been introduced to address this challenge. Active learning amalgamates the adaptability and intuition of the human mind with the computational prowess of machine learning. Through strategic selection of specific objects for expert labeling, active learning minimizes the volume of data requiring manual review by scientists while maximizing potential scientific outcomes.
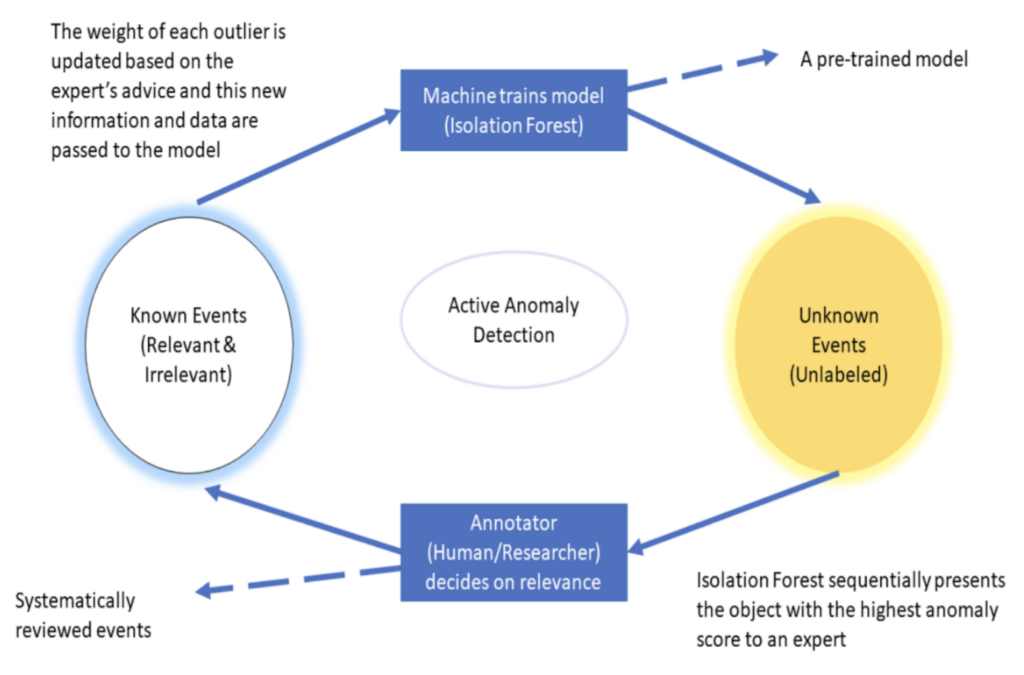
Active learning involves incorporating an expert’s advice as an extra step during the training of a machine learning classifier, as illustrated in Figure 2. Any standard unsupervised machine learning classifier can be utilized for anomaly detection. The expert can belong to any research domain and assign greater significance or score to the anomalies of particular interest to them. Some of the packages used for active learning in astronomy include ZWAD and ASTRONOMALY.
Thus, advancements in machine learning have significantly impacted the field of astronomy. Active learning, a promising area of research, proves highly beneficial in anomaly detection. This approach has been instrumental in analyzing extensive datasets and uncovering good features that would have been nearly imperceptible using traditional methods. Consequently, ongoing progress in machine learning is anticipated to continue playing a pivotal role in the future of astronomy, enabling scientists to make novel discoveries and attain deeper insights into the mysteries of our Universe.
Astrobite edited by: Katherine Lee
Featured image credit: H20 survey field (Subary Hyper-SuprimeCam, Euclid Data Field North)