Title: Scientific Text Analysis with Robots applied to observatory proposals
Authors: T. Jerabkova, H.M.J. Boffin, F. Patat, D. Dorigo, F. Sogni, and F. Primas
First Author’s Institution: European Southern Observatory, Garching, Germany
Status: Available on ArXiv
If you haven’t yet heard of ChatGPT, where have you been? (And can I come live there, too?) Its use as a kind of google-on-steroids has expanded greatly over the past couple of years, with its role in science becoming a major topic of conversation ever since. Regardless of your opinion on the morality of its use, the reality of it stands before us; What we can do now is continue to think critically about its limitations and the potential impact it can have upon science.
To this end, researchers at the European Southern Observatory (ESO) have decided to look practically at how ChatGPT can affect a scientists’ work, focusing on its effects in the processes of creating and reviewing observatory proposals. For those that aren’t familiar, to get the opportunity to take data with a telescope scientists must apply for their research ideas to be chosen by a panel of other scientists, usually through writing a proposal backing up their idea with scientific justification.
The STAR@ESO working group created an experiment aiming to test how proposals edited by ChatGPT would be graded relative to the originals crafted by scientists. To do this, they took five arbitrarily chosen pre-existing proposals written by scientists from ESO and ran them through ChatGPT with the instruction of “enhanc[ing] the scientific rationale.” This included directives such as “improving the text” to make it more appealing to “reviewers, who are astronomers,” “finding and citing appropriate scientific references,” and specifically to “structur[e] the rationale with an introduction, detailed science goals, expected outcomes, and a final summary.” These ChatGPT-edited proposals were then assessed through the Distributed Peer Review process, wherein researchers who have submitted a proposal agree to review proposals from their peers, assigning each proposal a final grade.
Or maybe don’t edit it…
To illustrate the effect ChatGPT can have on these proposals, the authors describe some qualitative differences between the original proposals and the ChatGPT-edited versions. They report that the ChatGPT versions are often longer and wordier than the originals when they are not given a strict word limit. They also note that in most cases, ChatGPT caused some scientific specificities to be lost, and in one it even incorrectly described what instrument the proposal was going to use. Even further, each title that ChatGPT came up with followed a similar structure: “Vague, Kind of Cliché Half-Sentence: Followed by Specific Scientific Title with Jargon” (I felt a bit called out by this one…)
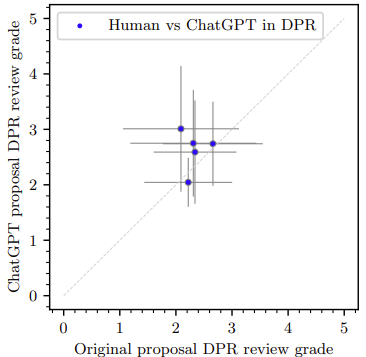
Figure 1: Comparison of scores given to original proposals vs. given to ChatGPT-edited proposals. A lower score indicates a more favorable proposal. The 1:1 ratio is given by the dotted line. Figure 1 in original paper.
To assess the quantitative differences in the scores given to the original vs. ChatGPT-edited proposals, the authors use a Bayesian inference approach with MCMC sampling to analyze the numerical difference between the scores. Proposals are typically scored on a scale of 1-5, with 1 being the highest-rated score. They found that the mean difference in the grade of the original proposals compared to the edited proposals was -0.18, i.e. that the edited proposals had a higher (and therefore, worse) score on average. From this they concluded that the edited proposals were scored significantly (statistically, anyways) worse than the original proposals.
ChatGPT practices self-love
The authors also tested how well ChatGPT did at scoring sets of proposals, asking the AI to give proposals a score ranging from 1-5 based on science relevance, quality, and impact. Ultimately, it was found that ChatGPT as a reviewer tended to score its own work a little higher than the original proposals. It also gave better reviews to every proposal overall, making it more difficult to distinguish which proposals should be given higher priority. The authors think this is because it didn’t tend to analyze any errors or shortcomings that the proposals may have–this is a very important aspect of reviewing and it seems that it takes a certain critical perspective that AI lacks.
They tested this analysis with different versions of ChatGPT (3.5 and 4), finding that the grades from each were quite different—for example, version 4 gave one proposal a 1.2 while version 3.5 gave the same proposal a 2.3. (If ChatGPT ever grades my proposal, here’s hoping it’s version 4 that does it.)
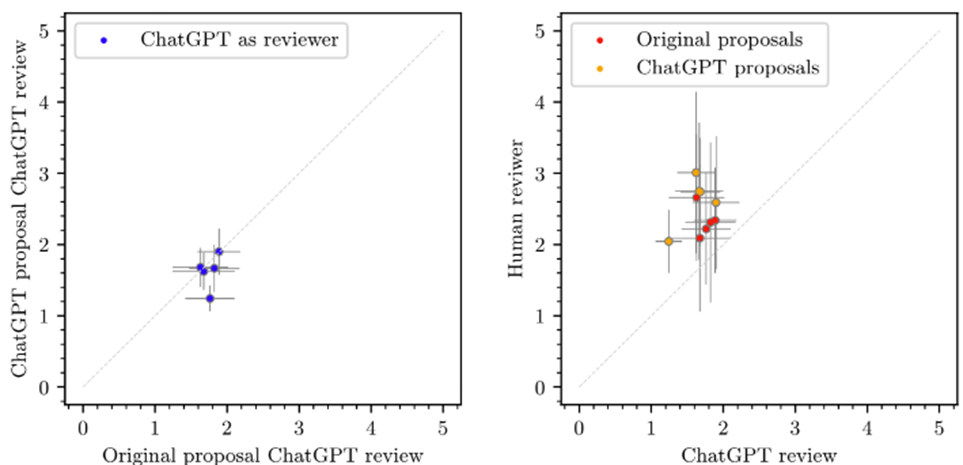
Figure 2. Grades given to original and edited versions by ChatGPT as a reviewer. Human reviewers scored proposals more harshly (left panel, the same proposals have higher scores when reviewed by a human reviewer than with ChatGPT review), and ChatGPT scored its own work better than human work (right panel, edited proposals reviewed by ChatGPT have lower scores than the same original proposals reviewed by ChatGPT). Figure 3 in original paper.
Another aspect this study explored was how good AI might be at creating references. Bafflingly, Google’s Gemini AI gave correct authors but an incorrect title, and ChatGPT entirely made up multiple references. Looks like we’re still stuck using Zotero.
The advantages of being human
The authors note that sharing content of proposals with ChatGPT is typically in breach of the observatory’s proposal confidentiality agreement, thus using it for review will likely not become a sanctioned activity. But for those that hope to edit their work with ChatGPT before submission, it’s not looking too good either, seeing that ChatGPT cannot always reliably or correctly describe the scientific content needed for proposals. What this work has shown is that proposals edited by ChatGPT do not match the quality of a human-written proposal by human standards; It seems we still have nuanced and valuable insight that no AI will ever be able to provide.
Studies like the one these authors have created can help us understand the material effects of using ChatGPT in specific settings, and moreover can inform how we should interact with these tools. It’s important to put our tools to the test and not get swept up in their fanfare without thinking critically about their effects on whole fields (not to mention their devastating effects on the climate!). If we don’t, the proposal and review process (and more generally, science and scientific research) could become AI grading AI, applauding itself over and over again for its good “work.”
Astrobite edited by Storm Colloms
Featured image credit: Caroline von Raesfeld
“we still have nuanced and valuable insight that no AI will ever be able to provide.”
Interesting prediction of the future. And here I thought we are astronomers not astrologers.