If you’ve ever taken a look up at a dark sky at night, your first reaction is probably one of awe. It’s a fair reaction — there’s a lot out there! So-called ‘deep field’ images — where we stare at an ostensibly ‘blank’ patch of the sky for a few hours with a telescope — reveal that what we can see with our eyes barely scratches the surface of the immensity of everything out there (for example, this JWST deep field revealed thousands of galaxies in a tiny sliver of the sky). Suffice it to say, space is big.
The sheer vastness of space means that studying the universe is a necessarily complex endeavor. Modern and forthcoming observational surveys collect enormous quantities of data — for example, once it is operational, the Vera Rubin Observatory will generate comparable amounts of data to all of X/Twitter’s daily web traffic, every night. Working to interpret this data can be equally complex. Modeling the structure and movements of stars in a galaxy, or galaxies in the universe is akin to following the patterns of cars in a city — all the drivers follow a base set of traffic rules (stars responding to physical laws, such as gravity) and respond to the behaviors of everything else nearby. It is as though we’re trying to understand where and what every car is doing in the biggest city in the world: a truly monumental computational task. As a result, in the era of the digital computer, astronomy is an increasingly computational field — much of the groundbreaking research undertaken today relies on numerical simulations of complex astronomical phenomena or requires manipulation of millions of observational measurements, all of which are housed on a supercomputer of some kind.
Who can access these resources?
Computing resources at the scale needed for such projects are expensive, and most universities do not have the in-house infrastructure for local research groups to access personalized compute power. Instead, the vast majority of scientists turn to national high-performance computing (HPC) facilities, such as at one of the national labs or other Department of Energy facilities, where massive supercomputers are managed. To gain access to such facilities, research groups need to submit computing proposals — much in the same way that one requests observing time — specifying the project goals and computational needs, and demonstrating past success in developing and using simulations. In effect, you need access to gain more access.
In such a framework, the challenges that could — and do — arise are fairly clear. For one, this requires that groups have consistent access to significant pots of grant money, which are increasingly difficult to obtain as the field expands. In a 2015 report, the NSF’s Astronomy and Astrophysics Advisory Committee (AAAC) highlighted that astronomy proposal success rates are falling (down to below 20% now), due entirely to the number of applicants rapidly growing while government funding stagnates (see the report here for more details). On top of that, success rates are even lower for new or unfunded researchers because of the so-called Matthew Effect, wherein more well-known, already funded scientists are more likely to receive higher proposal ratings and thus more funding. This in turn means that funding, resources, and research infrastructure tend to be concentrated at larger, wealthier institutions.
At the same time, astronomy faces a number of challenges associated with improving its demographic diversity. A 2012 report from the Executive Office of the President noted that, relative to the number of white students, the number of undergraduate students from underrepresented racial and ethnic groups planning to major in the physical sciences is already low (1.5% of the enrolled population). Of that small fraction, only 4% will end up studying physics or astronomy (compared to 11% of white students). Students and faculty from racial and ethnic minority groups are also not uniformly distributed in universities across the country — for example, a 2016 survey from the American Institute of Physics found that less than a third of astronomy departments across the country had any representation of Black or Latine faculty. As noted in the 2020 decadal survey on the state of the field of astronomy, this results in “institutions where most astronomers and students from underrepresented groups reside hav[ing] the least access and thus the least opportunity to engage in [computational research] and discovery.”
Learning to use computational tools
Access is not the only problem the field faces related to its (and the world’s) increasing computational dependence. Though simulations are now the primary tools used in theoretical astrophysics, they are still generally neglected in a standard curriculum. This seems — in part — to be an issue of perspective, as they are still seen as falling entirely under the umbrella of theory. While setting up a physics simulation still resembles work in theoretical physics, analyzing the results of a simulation generally has much more in common with experimental physics. In fact, some simulations are processed such that their outputs resemble mock observing programs, requiring an understanding of the details that go into inferring physical properties from various types of observations. On top of that, developing the software infrastructure for a multi-scale, multi-physics simulation environment can share many of the considerations that go into designing a laboratory or telescope facility. In this sense, a standard education program in physics and astronomy can and should incorporate training in all three pillars of modern physics: theory, experiment, and simulation.
Though computational research — in some form or another — is becoming the norm and increasing numbers of physics and astronomy graduates are turning to non-academic careers in data/computer science and engineering, course curricula and pedagogical approaches have not kept pace. For example, computer science/computational courses are not a standard requirement in physics and astronomy major curricula and most faculty have limited, if any, experience teaching computational methods to their students. This compounds the aforementioned issues of access and creates barriers for undergraduate students to effectively contribute to research earlier in their careers, thus disadvantaging them in the graduate school admissions process and job market as they complete their degrees.
Conventional academic pedagogical techniques are also ill-equipped to support computational methods training. Academic instructors often develop their own curriculum for every class they teach, so if instructors are not well-trained in computational methods, they are unlikely to incorporate such material into their courses. On top of this, technological tools advance at a rapid pace, requiring curricula to evolve with the field, more so than one would need for a standard physics course. While many institutions have well-defined infrastructure for developing skills in operating experimental and observational tools, analogous programs for interfacing with state-of-the-art high-performance computing facilities do not exist. This means that students end up informally picking up knowledge through research experiences or rely on the small number of computational summer schools that exist, which themselves are extremely oversubscribed and underfunded.
It is clear from all this that a closer attention to how computational tools are used and to whom they are distributed is a necessary component to the expansion and progression of the field moving forward. A shift towards using more open-source computing education modules in the classroom and increased funding opportunities (for scientists and training facilities) would certainly help mitigate some of these issues, and new tools and ideas could help tackle some of the systemic issues of access and education outlined above. Closer association with private foundations, philanthropic efforts, and industry partners — as recommended by the 2020 astronomy decadal survey — could help alleviate funding challenges and also create stronger pipelines for non-academic career outcomes in physics and astronomy.
Camber
One platform seeking to tackle some of these issues is Camber, a new company taking inspiration from infrastructure and workflows in the tech industry to streamline the astronomy research process. The schematic below summarizes the structure of their platform, which packages computational modules, simulation software, and storage tools in a simple interface for astronomy researchers and students to perform distributed computing (where several computers work together to perform a task) at low-cost. The user simply needs familiarity working with a Python environment (here manifested in JupyterLab) and the command line, and can then access a variety of “engines” through some simple import statements. For example, the current incarnation of the platform features science engines such as the stellar evolution code MESA and the hydrodynamic simulation code Athena++, and compute engines for parallel computing, such as OpenMPI. These engines are all fully integrated into the platform by the Camber team and are optimized for distributed computation, so any scientist, anywhere in the world, can develop sophisticated codes and efficiently deploy them without needing to specify anything about the infrastructure required, circumventing many of the complex barriers to entry present in most standard computational research pipelines today. All of this is connected to a flexible storage interface — the “stash” — which allows for easy data access and sharing on the cloud. By removing these barriers and streamlining the workflows, Camber hopes to democratize the scientific process and enable anyone to participate.
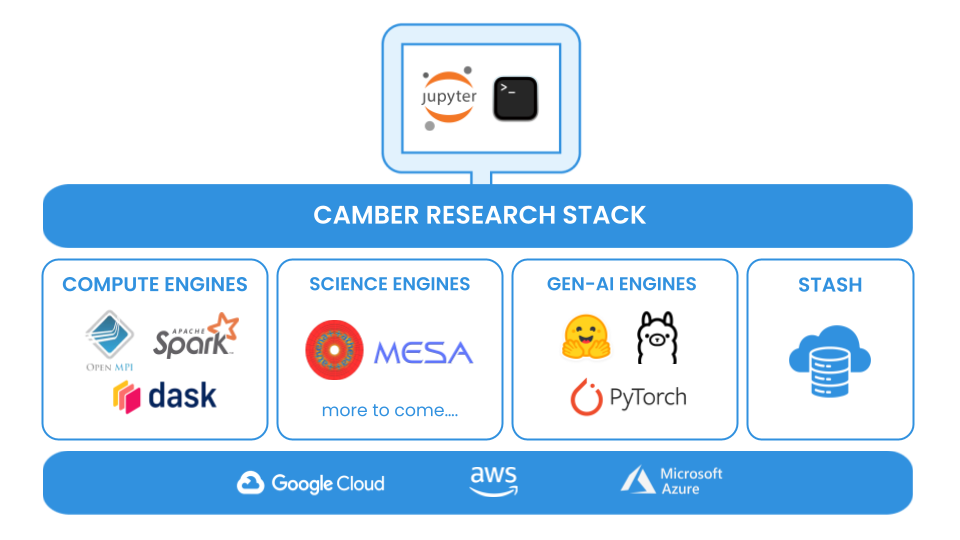
The Camber platform is young, but has already proven its value in a research environment, with customers at universities across the country. One of their biggest customers is the Institute for Advanced Study, where scientists have leveraged its capabilities to run magnetohydrodynamic simulations on the latest GPUs.
With these features, the Camber platform is also well-equipped to provide infrastructure for computational education at the collegiate and graduate levels. Though the platform is new, they have already demonstrated its capabilities through an NSF-sponsored summer school hosted by Professor Phil Chang at the University of Wisconsin-Milwaukee during 2023 and 2024. In a four week intensive camp, Prof. Chang invited 25 students from the Milwaukee metropolitan area to learn the basics of working with big data, high-performance computing, machine learning, and large language models from the ground up, all through the Camber platform. The platform has also been incorporated into the computational science and research training pathways offered through the Lamat Institute at UC Santa Cruz, where Camber’s low-cost, easy-to-use infrastructure is proving invaluable for the success of the program moving forward. The work done to leverage the platform for such initiatives — and their demonstrated success — provides a clear framework for computational education at scale.

International Computational Scholarships
Camber will be partnering with Astrobites to create a new fellowship series and support students interested in using this technology. In the first year, the plan is to award 100 students — primarily at the graduate level — with a certain number of “Camber Credits” to use the platform, with educational and technical support over the course of the duration of the scholarship. With this program, they hope to create a broad, supportive community of young researchers that spans geographic, racial, and economic boundaries.
As a first step, and to gain a better understanding of how to shape the program, please fill out the following survey.
The Camber platform is now live and can be accessed from their website. If you’re interested in exploring the platform, you can sign up for a free trial account here!
Featured image credit: Camber