Title: AI Cosplaying as Astrophysicists: A Controlled Synthetic-Agent Study of AI-Assisted Astrophysical Research Workflows
Author: Chun Huang
First Author’s Institution: Department of Physics and McDonnell Center for the Space Sciences, Washington University in St. Louis, St. Louis, USA
Status: Open access on the arXiv
Investigating the Russian Doll of AIs
Artificial intelligence is rapidly becoming part of the astrophysics workflow. From summarizing papers to debugging code and drafting text, many researchers now use large language models (LLMs) as everyday tools. But an important question remains: does AI actually improve astrophysics research, or does it just make us faster at making mistakes?
Today’s paper, which the author claims began as an April Fool’s bit, tackles this question in a creative way. The author simulates an entire population of “astrophysicists” and measures how well they perform common research tasks with and without AI assistance. The results suggest that AI can be helpful only in specific parts of the research workflow. For others, it can fail in ways that are particularly dangerous for science.
How many (AI) astrophysicists does it take…?
Instead of studying human researchers directly, the author runs a controlled synthetic experiment where AI models are like astrophysicists and complete realistic research tasks. The main experiment uses Qwen3:8B as the researcher and is later repeated with DeepSeek-R1:8B. Interestingly, the “AI assistance” in this experiment is not a separate model. Instead, the same model acting as the researcher is instructed to behave as if it were using AI in different ways. In other words, the experiment studies AI pretending to be researchers using AI. This allows the study to isolate how AI usage style affects research outcomes without changing the underlying model.
The study simulates 144 synthetic researchers with different career stages, different levels of AI awareness, and different tendencies to verify their work. These simulated researchers are given 2,592 astrophysics tasks covering common research activities such as writing, coding, literature review, derivations, and critique. Each task is completed once without AI assistance and once using different styles of AI assistance, resulting in 12,960 total task attempts. (See Figure 1.)
The study tests several different usage styles, ranging from cautious use with careful verification to overtrusting use where the AI output is mostly accepted unless something obviously looks wrong.
Where AI Helps — and Where It Doesn’t
This study mainly highlights how AI use in astrophysics is not binary, but highly task-dependent. AI assistance performs best on tasks like writing, summarizing literature, brainstorming ideas, and critiquing scientific claims. These are tasks where language and organization matter more than exact correctness. If the AI writes an awkward paragraph, you rewrite it. If it suggests a mediocre idea, you ignore it. The cost of being wrong is relatively low, and the researcher remains in control of the final result.
The worst category by far is derivations and quantitative reasoning. When tasks require algebra, unit conversions, or physical reasoning with multiple steps, AI assistance actually reduces performance and increases what the paper calls catastrophic failures, i.e., answers that are completely wrong but presented confidently and fluently. In derivation-heavy tasks, the AI often produces solutions that look scientifically convincing but contain arithmetic errors or unit problems.
One example described in the paper involves calculating the Eddington ratio of a black hole. The AI calculates a value of 560 when the correct answer is about 0.5, an error of three orders of magnitude. It also reports that it had verified the calculation and checked the units. This highlights the real danger of AI in technical science: it makes mistakes that look like they came from someone who knows what they’re doing.
Productivity vs. Catastrophic Errors
One of the most interesting results in the paper is that AI sometimes slightly improves average task performance, but at the same time increases the rate of catastrophic failures. In other words, AI may make researchers slightly more productive on average, while also making it more likely that they produce a result that is completely wrong. However, scientific research is not just about producing more text or more code; it is about producing correct results.
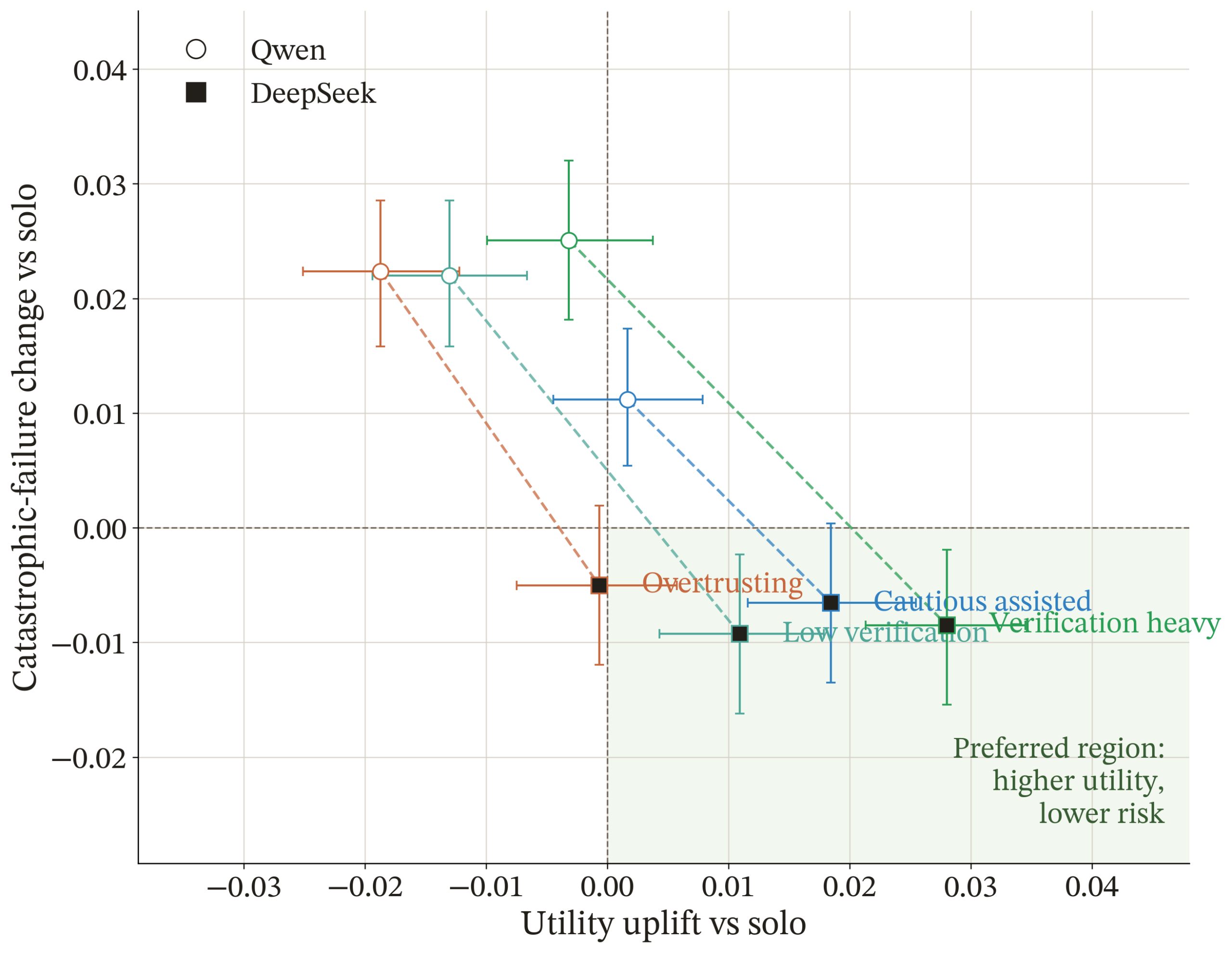
The tradeoff between productivity and risk is shown in Figure 2. The horizontal axis shows how much AI improves the overall usefulness of the work compared to working without AI, while the vertical axis shows how much AI changes the rate of catastrophic failures. Ideally, AI-assisted work would fall in the lower-right region of the plot, where utility is higher and catastrophic failures are lower. Instead, all of the AI usage styles increase the catastrophic failure rate, even when they slightly improve average performance. The paper finds that this excess risk is driven mainly by logic and reasoning tasks, where the AI is more likely to make serious mistakes that are difficult to detect. This figure summarizes the central result of the paper: AI can make some parts of research easier, but it can also make serious scientific errors more likely.
No Model-Agnosticism Here
As mentioned earlier, the experiment is first run with Qwen3:8B and then repeated with DeepSeek-R1:8B to test whether the results are model-dependent. The results change significantly between the two runs. When Qwen acts as the researcher, AI assistance slightly improves average performance but increases catastrophic failures, particularly in derivation and reasoning tasks. When DeepSeek acts as the researcher, AI assistance improves performance and reduces catastrophic failures.
This creates a practical problem: most researchers do not check which AI model is reliable for which type of task. In practice, people tend to use whichever model is available or convenient, even though this study suggests that the choice of model can significantly change whether AI helps or hurts the research workflow.
The Big Picture
The main takeaway from this paper is not that AI is universally good or bad for astrophysics. AI appears to be a useful tool for writing, summarizing, brainstorming, and critique, and a somewhat helpful tool for coding. However, it is much less reliable for logic-based operations and calculations, especially when used without careful verification.
The paper argues that the real question is not “Should we use AI in astrophysics?” but rather “Where can we use AI safely, and where do we still need to do the work ourselves?” For now, the answer seems to be that AI is good at producing text that sounds like science, but not always at producing correct science. AI can be a helpful tool, but it is indeed a tool that needs to be used carefully.
(See below1 for a personal note.)
Astrobite edited by Ben Sherwin
Featured image credit: Akshita Mittal
- Training and running LLMs requires significant computational resources, which translates into real electricity consumption and carbon emissions. Astrophysics already relies heavily on large computing facilities for simulations and data analysis, and adding widespread AI use on top of that raises a practical question about whether every task that can be done with AI should be done with AI. ↩︎