
Vivasvaan Aditya Raj is a first year graduate student in astrophysics at the University of Minnesota Twin Cities. He works with galaxy mergers and is currently developing a machine learning pipeline to identify and classify merger features in galaxy images.
Title: Re-envisioning Euclid Galaxy Morphology: Identifying and Interpreting Features with Sparse Autoencoders
Authors: John F. Wu, Michael Walmsley
First-author institution: Space Telescope Science Institute, Johns Hopkins University, University of Toronto
Status: Accepted to NeurIPS Machine Learning and the Physical Sciences Workshop. Shared via arXiv.
For more than a century, scientists have relied on their eyes to study galaxy morphology—the shapes and structures that reveal how galaxies form and evolve. This works well for thousands of galaxies, but it breaks down once the numbers reach the billions.
Euclid, a new ESA space telescope designed to map dark matter and dark energy, has already released millions of resolved galaxies in its Quick Release 1, and the full mission will deliver far more. Even with citizen science (projects on Zooniverse like Galaxy Zoo where volunteers classify galaxies), this scale is overwhelming. Rare structures, faint distortions, and unexpected companions can easily slip through the cracks simply because they don’t match the categories we already know.
Today’s paper asks a simple question with big consequences: can we use machine learning (models that learn patterns directly from images) not only to classify galaxies, but to discover new morphological features that humans have never defined?
Two Ways to Represent a Galaxy
The authors begin by creating two different ways of representing each Euclid galaxy, often called embeddings. An embedding is simply a compact numerical summary of an image that a machine learning model uses to understand what it is looking at.
One set of embeddings comes from a self‑supervised model (a model that learns from the image itself rather than from human‑defined classification labels) called a masked autoencoder (MAE), which is trained to reconstruct missing parts of an image. During training, most of each galaxy image is hidden, and the model learns to reconstruct the missing parts. Even with 90% of the image masked, the MAE recovers the overall structure with surprising accuracy.The authors also consider the embeddings produced by Zoobot, a supervised model trained on volunteer‑labeled galaxies, and show that the key results hold for both models.

Once these embeddings are created, the natural next question is: what exactly is inside them? What features is the model consistently paying attention to?
Opening the Black Box with Sparse Autoencoders
Deep learning models, like MAE, are very good at recognizing patterns in galaxy images, but they do it in a way that is hard for humans to understand. Inside the model, each galaxy is turned into an embedding, a long vector of numbers that encodes its key features. These numbers capture important information, but they do not tell us directly what the model thinks a spiral arm or a dust lane looks like.
To demystify this vector representation, the authors use sparse autoencoders, or SAEs. An SAE tries to break the model’s embedding into a set of directions, where each direction ideally corresponds to a single, recognizable idea, say whether the galaxy is a spiral, elliptical or irregular. This lets us ask what concepts the model consistently pays attention to across many galaxies.
To contextualise the efficacy of SAEs, the authors also compare this to a more traditional method called principal component analysis, or PCA. PCA looks for the strongest overall patterns in the data, but it does not try to isolate individual concepts. It is more like finding the main axes of variation in a cloud of points — broad trends rather than distinct features.
Together, PCA and SAEs give two different ways of peeking inside the model: one that captures broad trends, and one that tries to separate out distinct, interpretable ideas.

Do We have a Eureka!
It was observed that the PCA features behave as expected: the first few capture broad trends, and the rest quickly become hard to interpret.
SAEs, in contrast, produce features that stay interpretable even when you look at dozens of them. They also show stronger alignment with Galaxy Zoo labels (̉the classifications provided by volunteers in the Galaxy Zoo project) than PCA. In practice, this means that when volunteers say a galaxy has a bar, spiral arms, or is edge‑on, the corresponding SAE features tend to activate more strongly than the PCA ones. More interestingly, SAEs identified features that Galaxy Zoo never labeled, including subtle dust structures, faint companions, and other rare patterns. In other words, SAEs could highlight features that humans never defined but the model clearly recognizes.
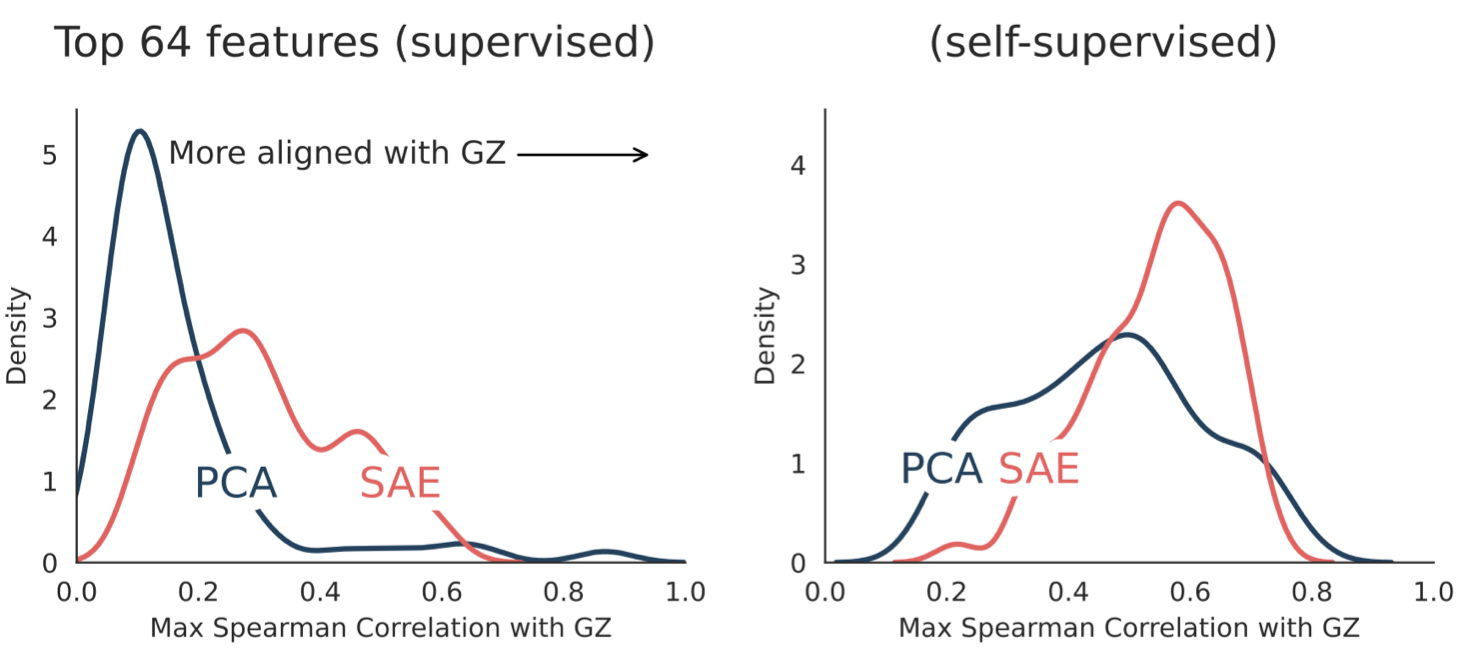
Moreover, the authors found that the MAE embeddings, which were trained with no labels at all, show stronger alignment with Galaxy Zoo labels than the supervised Zoobot embeddings. The authors suggested that this may be because the MAE must reconstruct everything in the image, including subtle structures and artifacts from telescope and detector imaging. That forces it to learn a broader set of features than a model trained only on human labels.
Why this Matters
Euclid will deliver more galaxy images than any human team could ever inspect, so we need tools that can reveal the unusual structures hiding in that flood of data. SAEs help by breaking a model’s internal representation into human‑readable pieces, revealing not just familiar categories but also features that no one ever labeled—dust lanes, faint companions, odd distortions, and other rare structures. As deep learning becomes central to astronomy, methods like SAEs give us a way to understand what these models actually learn and to use that understanding for discovery, not just classification.
Astrobite edited by: Chris Layden
Feature Image credit: NASA/ESA Hubble Images