
Vivasvaan Aditya Raj is a first year graduate student in astrophysics at the University of Minnesota Twin Cities. He work with galaxy mergers and is currently developing a machine learning pipeline to identify and classify merger features in galaxy images.
Authors: Popp, Jürgen J.; Dickinson, Hugh ; Serjeant, Stephen; Walmsley, Mike; Adams, Dominic; Fortson, Lucy; Mantha, Kameswara ; Mehta, Vihang; Dawson, James M. ; Kruk, Sandor ; Simmons, Brooke
First-author institution: School of Physical Sciences, The Open University, Milton Keynes MK7 6AA, UK
Status: Published in the RAS Techniques and Instruments Journal (January 2024) [open access]
The Undergraduate Research series is where we feature the research that you’re doing. If you are an undergraduate that took part in an REU or similar astro research project and would like to share this on Astrobites, please check out our submission page for more details. We would also love to hear about your more general research experience!
Who doesn’t enjoy looking at pretty images of galaxies? Neat spirals and ellipticals make some of the most sought-after computer wallpapers. Unfortunately, at higher distances, these same galaxies become irregular, messy shapes full of bright knots of star formation. These bright knots, formally known as Giant Star-Formation Clumps (GSFCs), are believed to play a significant role in galaxy evolution. The problem? GSFCs are fairly common around z~2, a time when the universe was only a few billion years old, but they are much rarer in the local universe. And without nearby analogues, it’s tough to piece together their full life story.
This is the problem the authors of today’s paper tackle. Popp et al. (2024) try to explore whether we can train machine learning models to find GSFCs in nearby galaxies so that we can study these objects more rigorously.
Why care about clumps?
Clumps are regions of intense star formation, spanning hundreds of parsecs and millions of solar masses. At high redshifts, they even dominate galaxy light profiles (a measure of how the brightness of a galaxy changes from its center to its outskirts). Despite this, we understand very little of their origins. Do they form when dense regions in gas‑rich disks collapse and trigger bursts of star formation, or are they created during mergers and interactions between galaxies? And what happens to them after they are born? Do they migrate inwards to build bulges or simply disperse into disks?
A systematic study of these clumps to answer these questions requires samples of GSFCs across all timescales. With surveys such as The Sloan Digital Sky Survey (SDSS) and The Dark Energy Camera Legacy Survey (DECaLS), we have a robust sample of galaxies across various redshifts. However, the resolution of these images is often too low to search for clumps. And while human volunteers at Galaxy Zoo help, scaling the sample to tens of thousands of images simply needs automation.
Enter Deep Learning
To make this endeavor a reality, the authors turned to Faster Region‑based Convolutional Neural Networks (Faster R‑CNNs), a machine learning model used in facial recognition devices and self-driving cars. Unlike other models, Faster R-CNNs identify specific objects in each image by drawing bounding boxes around them, making the model ideal for this work.
The only problem with using Faster R-CNNs is that the model’s backbone is trained on ImageNet. ImageNet is a dataset containing millions of images of everyday objects such as cats, cars, and coffee mugs. Since none of these objects resemble galaxies, the authors created a domain-specific backbone, Zoobot. The backbone is the part of the network that extracts features from an image. Zoobot was trained specifically on over a million galaxy images to enhance its capabilities in extracting astronomy specific features. Following the backbone training, the authors integrated Zoobot with FAST R-CNN for testing. In machine learning jargon, they performed Transfer Learning, where the knowledge from one task is reused to boost the performance of another.
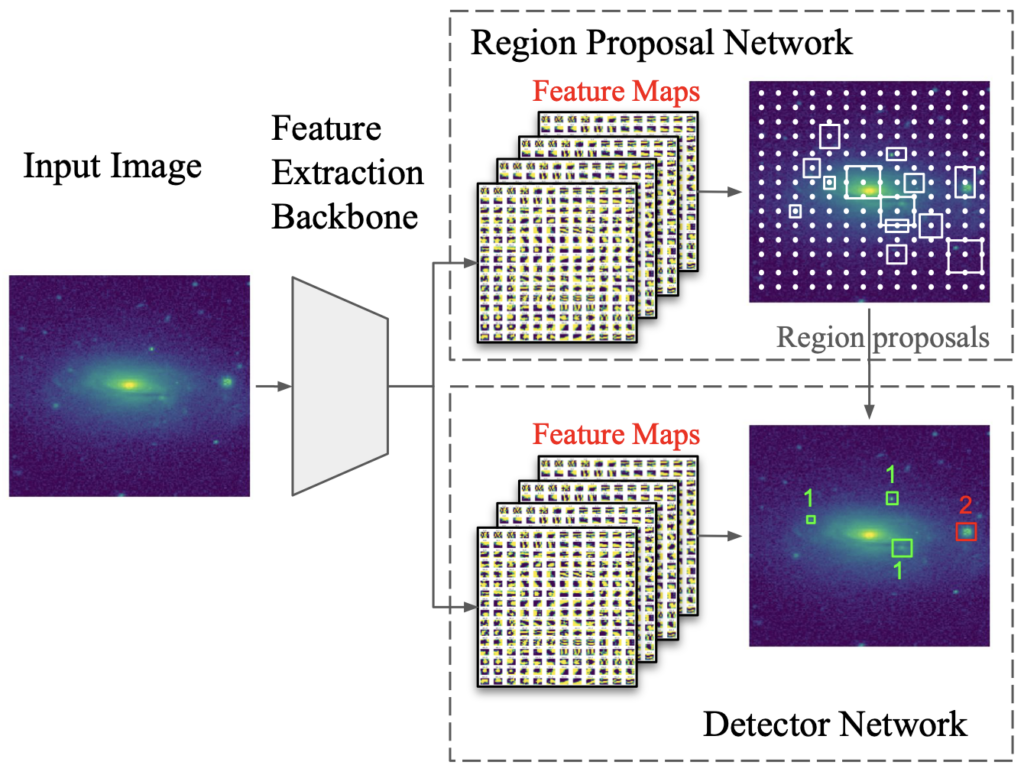
Train that machine
The training data for the models came from Clump Scout, a Galaxy Zoo project where volunteers marked clumps in about 50,000 SDSS galaxies. To ensure precision and completeness, each image was inspected by 20 volunteers and their annotations aggregated. After cleaning the data, the authors collected over 18,000 galaxy images with about 40,000 clumps.
Using this data, they trained five versions of Faster R-CNN, varying the backbone (ImageNet vs. Zoobot) and whether the model was trained on clump-specific datasets. They further trained each model on subsets of their data to measure how model accuracy varied with sample size.
And we have a winner!
Comparing the performances of these five models revealed a clear outcome. The Zoobot models performed significantly better than the ImageNet ones. Even with “small” datasets of 5000 galaxies, the Zoobot models detected clumps with a completeness and purity level of 0.8. In simple words, the models found most of the clumps and produced very few false positives. This significantly improved performance resulted from training the network on astronomy‑specific images, rather than generic ones.
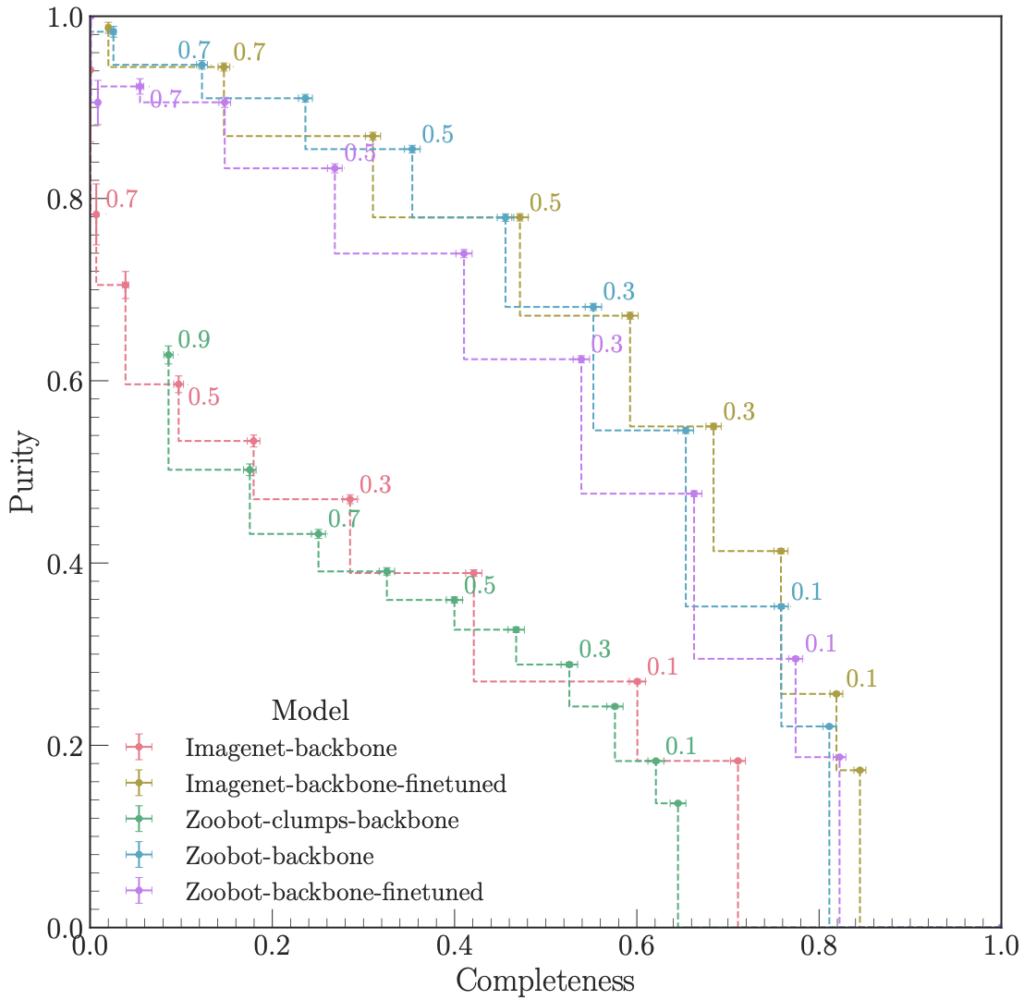
The ImageNet models, on the other hand, often overfit and required much larger datasets to achieve acceptable accuracy. Simply put, the ImageNet models would memorize the training data but struggle with new images, requiring more training to “learn” rather than “memorize”.
Pretraining the model on galaxy images had given the network a huge headstart in recognizing astrophysical features.
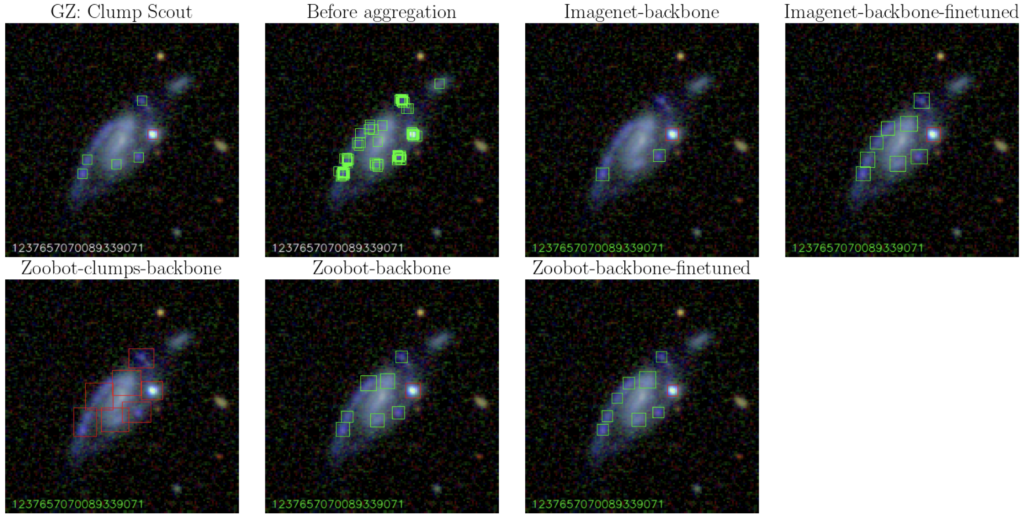
Why this Matters
This work highlights how astrophysics can benefit from a partnership between humans and machines. Citizen Science volunteers can help create the training data, and domain machine learning models can use it to unlock new science from existing surveys. With upcoming missions like Rubin and Euclid set to deliver petabytes of imaging data, automated processes like these can greatly increase our scientific efficiency.
This work also highlights the power of transfer learning in astronomy. Instead of starting from scratch for every new project, we can build on models already trained on similar data. This way, we would need less training data and achieve faster convergence and better accuracy.
The Big Picture
Clumps are crucial to our understanding of galaxy evolution. Studying them can yield novel insights into star formation, feedback, and galaxy interactions. And with these machine learning tools, we can accelerate our search for them at all redshifts and connect the dots between the messy galaxies of the past and orderly spirals and ellipticals of today.
In short: citizen scientists marked the clumps, Zoobot learned the patterns, and Faster R‑CNN turned it into a scalable tool. The result is a path forward to study one of the most striking features of galaxy evolution, one bounding box at a time.
Astrobite edited by: Joe Williams
Feature Image credit: NASA/ESA Hubble Images, T. Johnson.