Title: Machine Learning and Cosmological Simulations – II. Hydrodynamical Simulations
Authors: Harshil M. Kamdar, Matthew J. Turk and Robert J. Brunner
First author’s institute: Department of Physics and Department of Astronomy, University of Illinois, Urbana, USA.
Paper status: Published in MNRAS, 2016.
Our universe consists of baryons (normal matter), dark matter, and dark energy. When galaxies were being assembled, the contribution of dark energy was negligible due to its low density. Galaxy formation is a duet by dark matter and baryons. Dark matter first sets the stage by piling up into “cradles” of galaxy formation known as dark matter halos. Galaxies then form as gas gets collected and cools at the centers of these halos.
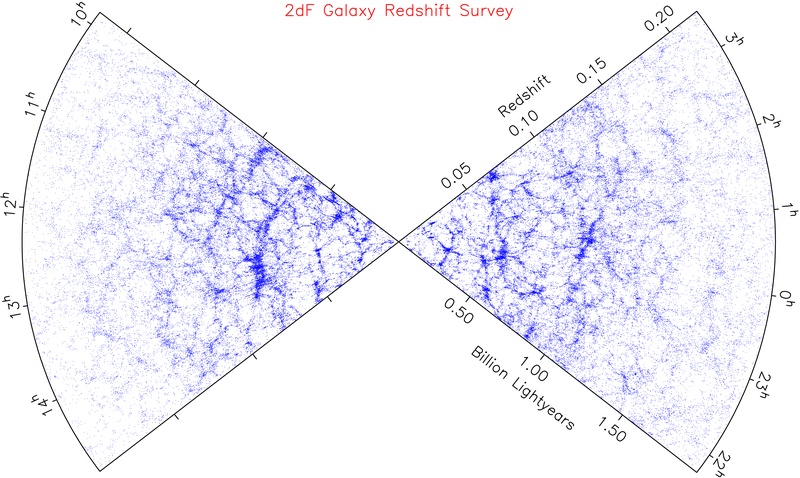
On large scale the only relevant physics is gravity on dark matter, and we understand gravity very well. Calculations with only dark matter and gravity, also known as N-body simulations, were able to reproduce the observed large-scale structure of galaxies (compare the 2dF galaxy map with the Millennium simulation), but we cannot directly observe dark matter. We can see stars and gas on much smaller galactic scale, but the baryonic physics is very complicated and some of which are poorly known. Therefore, being able to connect galaxy properties with the properties of their host halos provides crucial information on how galaxies form and evolve throughout cosmic history.
{kind=link}

Figure 1. Projection of dark matter (left) and gas density (right) centered on the most massive galaxy cluster in the Illustris simulation (snapshot at z = 0).
Attempts to construct the halo-galaxy relation typically involve numerical simulations. On top is the projection of dark matter density (left) and gas density (right) centered on the most massive galaxy cluster in the Illustris simulation project. Illustris simulates galaxy formation by evolving dark matter and gas dynamics alongside each other. The halo-galaxy relation can thus be derived simply by “observing” the Illustris-universe. This gravity + hydrodynamical approach is accurate, but is computationally extremely demanding. For example, the Illustris project took ~19 million CPU hours to run, which is equivalent to ~520 years on your new quad-core personal computer! Another common approach is to “paint” galaxies onto backdrops of dark matter-only simulations using pre-derived, physically motivated recipes. This two-step, semi-analytical approach is less exhausting, but still require ~10,000 CPU hours to create a universe with similar resolution.
The authors of today’s paper take a fundamentally different approach – rather than considering the physical processes that go into forming galaxies, they leave the hard work to the computer using machine learning algorithms. Machine learning trains computers to recognize underlying relations in large datasets which are otherwise incomprehensible to human. Machine learning has been applied in astrophysics in various contexts, from finding transient objects in the sky, to classifying holes on the Sun, to classifying quasars and shapes of galaxies. The machine learning scheme in today’s paper is technically known as supervised learning.
The idea of supervised learning is very straightforward – similar to how you learn from experience. For example, judging from the inside of a restaurant, you can probably give a ballpark estimate of how much it costs for dinner before looking at the menu. You learn to make predictions (of dinner costs) by internalizing input data (experience paying at hundreds of restaurants). What computers can do better is that they can take in a larger volume of data in much shorter time – this is precisely the strength of machine learning.
The authors used the same idea for this paper, only the input data becomes the halo properties and the desired outputs or predictions become the galaxy properties. From the Illustris simulations, the authors extracted a catalog of halo-galaxy properties, i.e., input-output pairs. The computer is then trained with a quarter of this catalog, effectively creating the experience of looking through millions of galaxies. It can then “figure out” a model to predict galaxy properties based on the halo properties. The goodness of the model is then evaluated by comparing its predictions with the “model answers” of outputs in the remaining three quarters of catalog.
In the original paper, predictions of a series of galaxy properties at different redshifts are reported. Here we will just illustrate the idea using one of the properties, namely, the total stellar mass of the galaxy. Figure 2 shows the hexbin plot of the predictions versus the catalog “model answers”, with the diagonal black dashed line representing perfect predictions. The color of the pixels represents, in logarithmic scale, the number of galaxies with certain accuracy. It shows that the predictions almost align perfectly with the diagonal, with larger scatters only at low stellar mass.
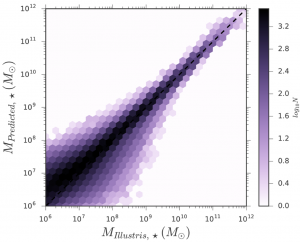
Figure 2. Hexbin plot of the predicted stellar masses in the galaxies versus the catalog values in the Illustris simulation at redshift z = 0. The black dashed line corresponds to perfect prediction.
Alternately, we can look at the distributions of stellar mass in the predicted and the cataloged populations of galaxies, which is shown in Figure 3. Again we see that the machine learning predictions are almost exact. Both plots suggest that the machine learning-predicted population of galaxies closely resembles the actual Illustris-simulated population. Predictions of other properties such as star formation rate and stellar metallicity are not as perfect, but still fairly robust.
Simply looking at the plots seems to suggest machine learning works magically. It doesn’t. machine learning does not create models for predicting galaxy properties out of nowhere, it derives them by mathematically synthesizing the halo-galaxy catalog used in the training step, which is in turn the product of high-resolution simulations including detailed physics.
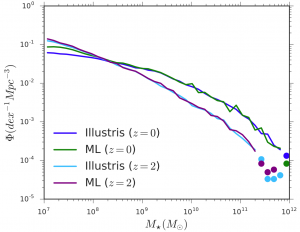
Figure 3. The number density (number per cosmic volume) of galaxies with different stellar masses, for both the predicted (ML) and cataloged (Illustris) populations. The color dots denote number density bins with less than 20 galaxies.
It is worth re-iterating that the machine learning approach discussed here makes no reference to any kind of physics whatsoever. The machinery of machine learning is not meant, to say nothing of the ability, to replace physical simulations. It does have several advantages over them: (1) machine learning is able to make robust predictions of the galaxy properties given only the halo properties; (2) machine learning is extremely efficient. Populating dark matter halos with galaxies takes orders of a few minutes; (3) machine learning is simple. It does not require any prior knowledge of halo-galaxy relation. With these, machine learning bears the potential to quickly mimic hydrodynamical simulations, making it a profitable analysis tool for exploring the influences of various physics on structure formation. And what’s more, the first author of today’s paper is an undergraduate researcher! Here we are only showcasing one of the many great work astronomy undergrads are doing!
Author
Trackbacks/Pingbacks