- Title: Automated Transient Identification in the Dark Energy Survey
- Authors: D. A. Goldstein, C. B. D’Andrea, J. A. Fischer, et. al
- First Author’s Institution: U. C. Berkeley
The problem of Big Data in Astronomy
Astronomers work with a lot of data. A serious ton of data. And the rate at which telescopes and simulations pour out data is increasing rapidly. Take the upcoming Large Synoptic Survey Telescope, or LSST. Each image taken by the telescope will be several GBs in size. Between the 2000 nightly images, processing over 10 million sources in each image, and then sending up to 100,000 transient alerts, the survey will result in more than 10 Terabytes of data… EVERY NIGHT! Throughout the entire project, more than 60 Petabytes of data will be generated. At one GB per episode, it would take 6 million seasons of Game of Thrones to amount to that much data. That’s a lot of science coming out of LSST.
One of the largest problems with handling such large amounts of astronomical data is how to efficiently search for transient objects: things that appear and disappear. A major challenge of transient astronomy is how to distinguish something that truly became brighter (like a supernova) from a mechanical artifact (such as a faulty pixel, cosmic ray, or other defect). With so many images coming in, you can’t retake them every time to check if a source is real.
Before the era of Big Data, astronomers could often check images by eye. With this process, known as “scanning”, a trained scientist could often distinguish between a real source and an artifact. As more images have come streaming in, citizen science projects have arisen to harness the power of eager members of the public in categorizing data. But with LSST on the horizon, astronomers are in desperate need of better methods for classifying images.
Bring in Machine Learning
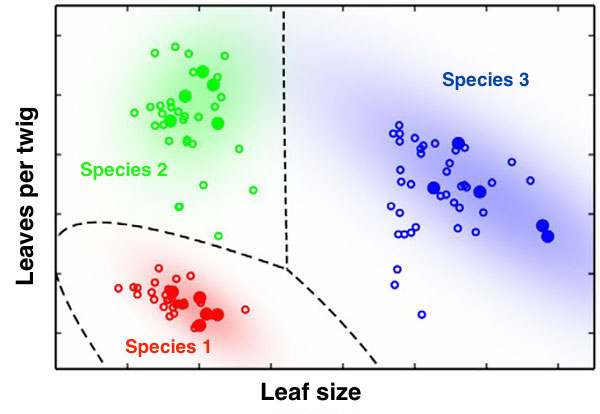
Fig. 1 – A visual example of a machine learning classification problem. Here, trees are sorted by two features: leaf size and number of leaves per twig. The training set (open points) have known classifications (Species 1, 2, or 3). Once the training set has been processed, the algorithm can generate classification rules (the dashed lines). Then, new trees (filled points) can be classified based on their features. Image adapted from http://nanotechweb.org/cws/article/lab/46619
Today’s paper makes use of a computational technique known as machine learning to solve this problem. Specifically, they use a technique known as “supervised machine learning classification“. The goal of this method is to derive a classification of an object (here, an artifact or a real source) based on particular features that can be quantified about the object. The method is “supervised” because it requires a training set: a series of objects and their features along with known classifications. The training set is used to teach the algorithm how to classify objects. Rather than having a scientist elaborate rules that define a classification, this technique develops these rules as it learns. After this training set is processed, the algorithm can classify new objects based on their features (see Fig. 1).
To better understand supervised machine learning, imagine you are trying to identify species of trees. A knowledgeable friend tells you to study the color of the bark, the shape of the leaves, and the number of leaves on a twig — these are the features you’ll use to classify. Your friend shows you many trees, and tells you their species name (this is your training set), and you learn to identify each species based on their features. With a large enough training set, you should be able to classify the next tree you come to, without needing a classification from your friend. You are now ready to apply a “supervised learning” method to new data!
Using machine learning to improve transient searches
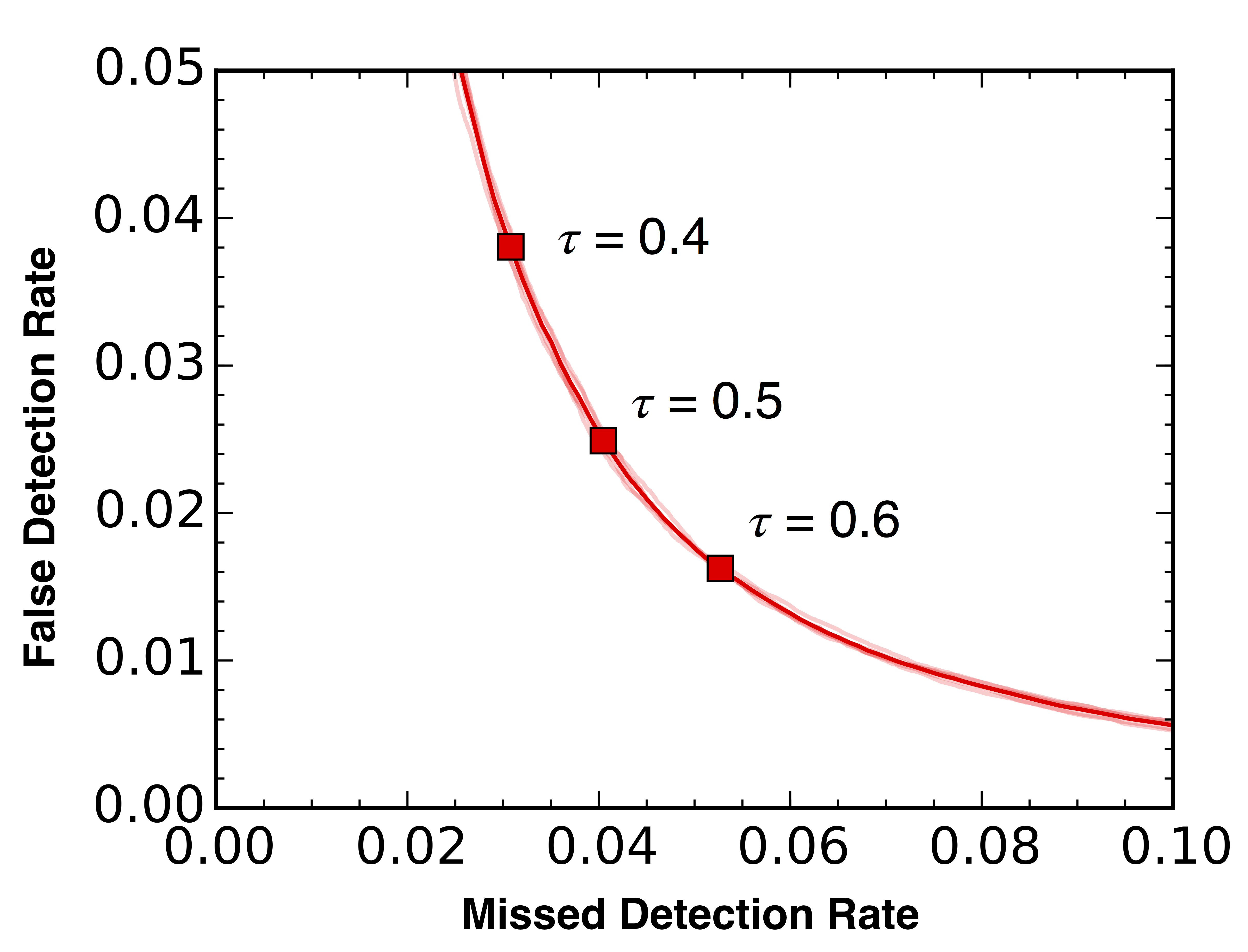
Fig. 2 – The performance of the autoScan algorithm. The false detection rate is how often an artifact is labeled a true source. The missed detection rate (or false-negative rate) is how often real sources are labeled as artifacts. For a given tolerance level (tau), the authors can select how willing they are to accept false positives in exchange for lower risk of missing true sources. The authors adopted a tolerance of 0.5 for their final algorithm. This level correctly identifies real sources 96% of the time, with only a 2.5% rate of false positives. Fig. 7 from Goldstein et al. 2015.
The authors of today’s paper developed a machine learning algorithm called autoScan, which classifies possible transient objects as artifacts or real sources. They apply this technique to imaging data from the Dark Energy Survey , or DES. The DES Supernova program is designed to measure the acceleration of the universe by imaging over 3000 supernovae and obtaining spectra for each. Housed in the Chilean Andes mountains, DES will be somewhat akin to a practice run for LSST, in terms of data output.
The autoScan algorithm uses a long list of features (such as the flux of the object and its shape) and a training set of almost 900,000 sources and artifacts. After this training set was processed, the authors tested the algorithm’s classification abilities against another validation set: more objects with known classifications that were not used in the training set. AutoScan was able to correctly identify real sources in the validation set 96% of the time, with a false detection (claiming an artifact to be a source) rate of only 2.5% (see Fig. 2).
With autoScan, the authors are prepared to analyze new data coming live from the Dark Energy Survey. They can greatly improve the efficiency of detecting transient sources like supernova, by easily distinguishing them from instrumental artifacts. But better techniques, such as more clever development of training sets, will continue to beat down the rate of false positives.
Machine learning algorithms will become critical to the success of future large surveys like LSST, where person-power alone will be entirely insufficient to manage the incoming data. The same can be said for Gaia, TESS, the Zwicky Transient Facility, and pretty much any other upcoming astronomical survey. Citizen science projects will still have many practical uses, and the trained eye of a professional astronomer will always be essential. But in the age of Big Astro, computers will continue to become more and more integral parts of managing the daily operations of research and discovery.
Author
This seems like a great use of computer algorithms to handle massive data, and to further our understanding of astronomy!
Exciting to hear that steps are already being made toward automating some of the data analysis and reduction involved in astronomy research. It seems now that with all the new instruments and avenues of approach, the data received can be quite overwhelming and now it has become a problem of manpower for some, this is where I see research going in the next few decades.
How large of a computer or how much computing power would be needed to run such algorithms? Is this something that can be done with a personal device?
Great question, Chris! The authors answer this for both steps of the process (training the algorithm, and classifying new data). They say that it took 4.5 minutes to train the algorithm with the 900,000 training points, when run on 60 cores of a computing cluster. That suggests it’s feasible-ish on a personal computer (taking a few hours, perhaps), but I’m not sure about how memory was handled. The second step of predicting classes for 200,000 new data instances took only 9.5 seconds on a single core! The training procedure seems to be the most computationally intensive, while use of the already-trained algorithm is extremely fast!
Have any older datasets been re-analyzed using this method? Since this machine learning algorithm improves accuracy, it might be a useful tool to confirm past findings as well. I wonder what scale of differences in results would be found.
It’s incredible that so much data can be examined in only a few hours or less, saving hundreds of hours of human time!
What do you do with the data once it has been accumulated and analyzed? What measures are put into place so that those massive quantities of data are stored in a cost-efficient and easily accessible way?
It’s amazing to see how quickly we are adapting to greater and greater amounts of data! Will there ever be a limit to our capabilities at this?
This is an awesome development. It’s amazing that we’ve gotten by on human analysis without this up until now.
I had a similar question to Chris above, so I checked about Ben’s reply to his question. It’s great that the training procedure is what’s computationally expensive, since it should be easy to do any training on powerful clusters and then distribute the less computationally expensive trained algorithms to researchers/amateurs for use on their PCs.