Title: Stellar classification from single-band imaging using machine learning
Authors: T. Kuntzer, M. Tewes & F. Courbin
First Author’s Institution: Laboratoire d’astrophysique, École Polytechnique Fédérale de Lausanne (EPFL)
Status: Published in Astronomy & Astrophysics, open access
A fundamental property of a star is its effective temperature, which observational astronomers like to express in terms of a spectral type or color. A hot star of class O, for example, emits more light at shorter wavelengths, which makes it bluer than a colder star of class G or M (spectrally speaking). Ideally, the spectral type of a star is determined from a high-resolution spectrum. The next best thing would be to know its brightness in at least a few different wavelengths bands. For a large sample of stars, this method (multi-band photometry) is usually the most efficient. It might seem unintuitive, but the authors of today’s paper show that under certain conditions a star’s spectral type can also be determined accurately from a single-band image only, using supervised machine learning techniques.
How It Works
There is a subtle effect that makes stars with different spectra appear just slightly differently. Each star is a point-like source of light, that when imaged by a telescope produces a diffraction pattern called the point spread function (PSF). But the PSF changes with wavelength and so the exact shape of a star’s image depends on the characteristics of both the instrumental transmission profile and the stellar spectrum, in some complicated way (Fig. 1). The wider the accessible wavelength range, the larger these small differences become. However, to be able to exploit them, it is necessary to obtain sharp (diffraction-limited) images under extremely stable conditions. That is why the authors mainly test their method on mock data that Euclid, a next-generation space telescope, is expected to deliver, but the same method could be applied to existing Hubble Space Telescope data as well.

Figure 1: Simulated images of stars with different spectral types and, in the second row, the small but significant differences between these images. (Figure 1 in the paper.)
To classify a star in practice, it is necessary to pre-process and simplify the data first. The authors choose a procedure called principle component analysis to reduce a thumbnail image of each star into a set of numbers that describe a point in a ‘feature space’, a lower-dimensional representation of the image. In this representation, the value in each dimension corresponds to the strength of a particular difference or ‘feature’ in the shape of the PSF.
In a next step, the authors train an artificial neural network to find an optimal mapping between these points in feature space and the different spectral types. The data set used for this purpose should be extensive and only contain high-quality images of stars with well-known spectral types. In principle, it is possible to compile a training set from either realistically simulated data or actual imaging and spectroscopic observations. Finally, the trained network can be used to estimate the spectral type of a star from a given input image.
The fundamental idea behind using a neural network for classification tasks is to automatically generate a large but fundamentally simple model, instead of trying to construct some very complex model manually. But the challenge is to optimize a large number of model parameters in a reasonable amount of time, while avoiding over- or under-fitting. That generally requires some experimentation and the authors also note other viable algorithms such as random forests.
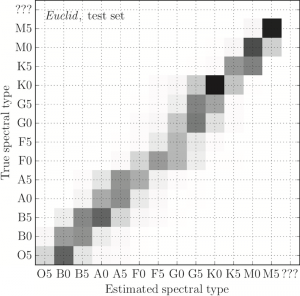
Figure 2: A confusion matrix showing the performance of the machine-trained stellar classifier on simulated but realistic Euclid data. A perfect classifier would produce a thin diagonal line in this graphic. The label ‘???’ is assigned to objects that are not stars or images that could not be classified. (Figure 8 in the paper.)
A Proof of Concept
It works! The neural network, properly trained on the mock Euclid data, turns out to be very successful at classifying main sequence stars. A useful chart to check results visually is the confusion matrix (Fig. 2), which shows the deviation between the estimated and the actual spectral types of stars in a test set. The typical prediction error is not more than half a spectral type. Interestingly, most errors occur in the case of G and K stars, which is due to the similarity of their spectra, and the classification of redder stars is more successful overall.
Most importantly, the authors have demonstrated that stellar classification based on only a single broad-band image is feasible. The classification proves to be reliable in the presence of noise and robust against astrophysical complications such as reddening by interstellar extinction or companion objects. Real-world performance remains to be tested when Euclid is launched (no earlier than 2020), but machine learning techniques will certainly allow a quick first classification, even of faint stars, which may otherwise never get classified.
The authors have also demonstrated first-hand that advanced computational methods such as machine learning can yield valuable information when applied to astronomical data sets, sometimes in ways that are not even anticipated. If you would like to learn more about other uses of machine learning in astronomy, you can start by reading previous astrobites on the automatic ideentification of transient objects or the measurement of photometric redshifts.
Author
Trackbacks/Pingbacks