- Title: Measuring photometric redshifts using galaxy images and Deep Neural Networks
- Authors: Ben Hoyle
- Author’s Institution: Ludwig-Maximilians University, Munich
- Paper Status: Accepted by Astronomy and Computer Science
Astronomy is beginning to enter the age of “Big Data“, with upcoming surveys like LSST anticipated to gather upwards of 10 Terabytes of data per night. Astronomers are becoming increasingly concerned with how to process this data both rapidly and accurately.
The obvious solution is to automate the process, allowing clever computer algorithms to crunch the data as soon as it comes in. The field of machine learning is proving extremely useful, because it lets the computers derive connections between the data without requiring astronomers to analyze the full datasets by hand. The goal of today’s paper is to study the potential for an advanced machine learning method known as neural nets to improve our ability to automatically analyze data taken straight from the telescope.
————–
Side Note: for those readers interested in learning more about the inner workings of neural nets, check out this free online textbook on the subject. The book walks the reader through simple steps towards developing a neural net to recognize handwritten digits. Very minimal math or coding background is required.
————–
Machine Learning in Astronomy
At its core, the goal of machine learning is to allow a computer to draw connections between data. One classic example is “classification“, which gives an object a particular label if its properties are similar enough to already seen-and-labeled data. In a previous Astrobite, we discussed a paper which used machine learning to classify possible “transient” objects. Data about each possible object (including its flux, shape, and position) were used to verify whether the source was real or simply an artifact.

Figure 1: A Deep Neural Network (schematically shown) is used to convert raw galaxy images (top) into predicted redshift bins (bottom). The algorithm includes many interconnected layers of analysis with many steps. But each step is not set by hand, but is tuned automatically to fit a series of training data. Only 5 layers of the network are shown, but there are 23 layers in all.
The data values which are used as input to a machine learning algorithm are called features. In many cases, machine learning applications for astronomy have relied on using highly pre-processed features, rather than working from the raw data. In the previous example, the flux, shape, and position of a potential source are not part of the raw data. They are computed from a previous step, where a human works to break each image up into many potential sources. The properties of each are then passed as features to the machine learning algorithm for verification.
A very advanced set of machine learning tools called Deep Neural Networks (DNNs or “neural nets”) have the potential to streamline how data is analyzed, by eliminating the need for a pre-processing step. Specifically, this paper demonstrates using a DNN to predict a photometric redshift from the raw images of galaxies.
From Pixels to Redshifts
Rather than measuring a galaxy’s redshift (a proxy for its distance) directly from its spectrum, the photometric method predicts a redshift by using only the galaxy’s colors. Traditionally, information about the galaxy must be heavily pre-processed, such as by fitting a profile to measure its size. Then, the galaxy’s colors are measured using photometry in several different bands. The author of today’s paper used these features (size and color) as inputs to a traditional machine learning algorithm called AdaBoost, which is used as a “baseline” model.
The author then used a complex DNN to predict a redshift using the raw galaxy images alone. The features are thus the individual pixel values, rather than pre-processed quantities like “size” and “color”. These features are passed through an extremely complex series of computational layers (23 steps in all, schematically shown in Figure 1) to finally produce a predicted redshift. How did the neural net approach compare to the traditional machine learning algorithm?
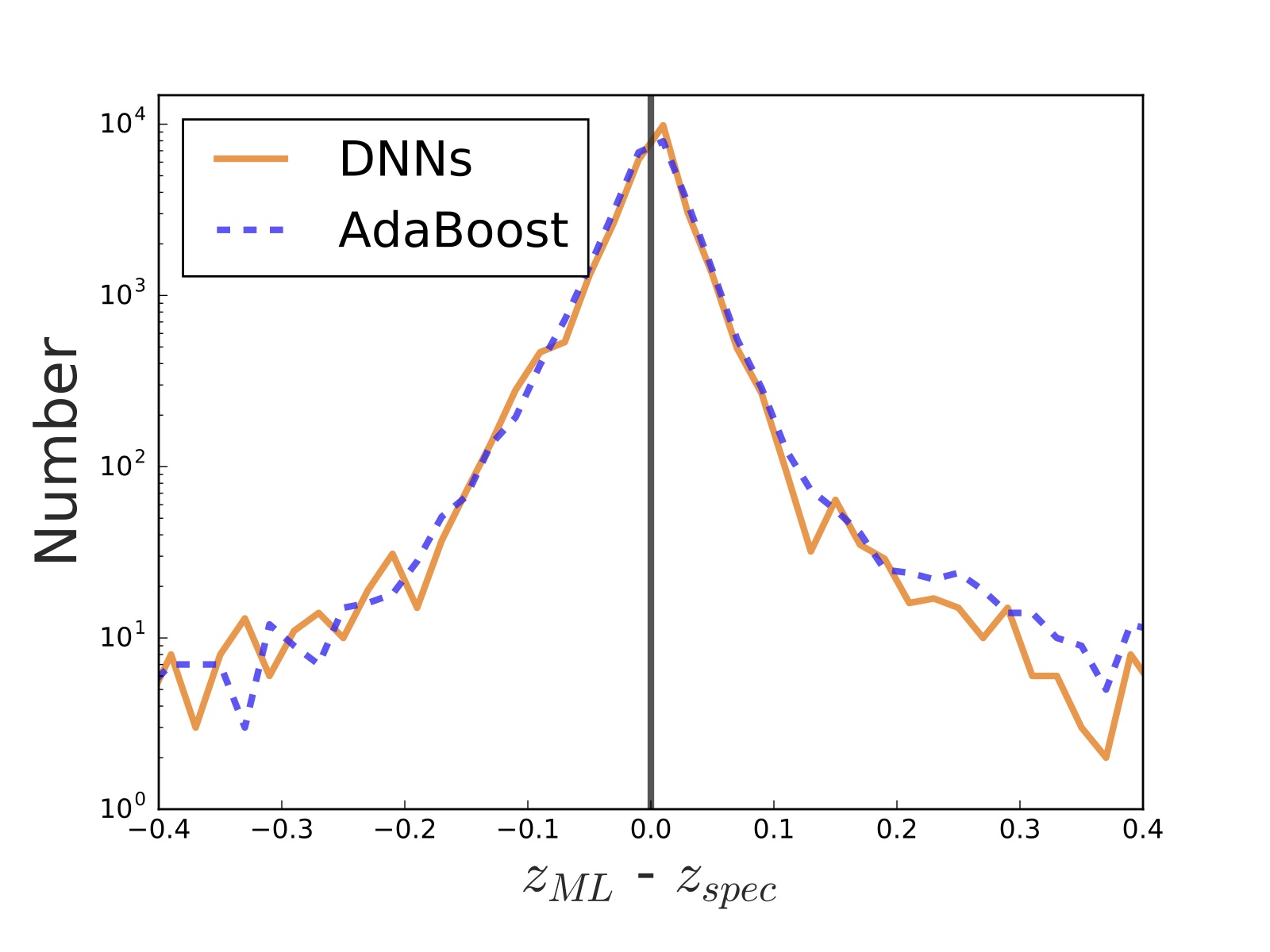
Figure 2: These histograms show the distribution of errors: how far off the predicted redshifts are from the true spectroscopic values. Both methods did just about as well (were usually off by less than 0.2) but the much simpler AdaBoost method took 100,000 times less time than the complex DNNs.
Similar Results, Very Different Runtimes
Both methods are based around machine learning, which means that each algorithm adapts to best replicate over 30,000 training examples. The performance of each method was then tested by comparing the redshift predictions made on a separate sample of 30,000 test galaxies against their true spectroscopic redshifts.
Figure 2 shows the distribution of errors between the two methods. AdaBoost and the DNN are almost identically accurate, making predictions to within an error of 0.2 in almost all cases. This is a significant milestone for the neural network method, as it shows that it is possible to create an algorithm which predicts redshift accurately from the raw images alone.
Unfortunately, the DNN method was much much slower than the baseline machine learning method. Both the training and testing phases for the neural nets took a whopping 100,000 times longer than AdaBoost.
The author emphasizes that neural nets are approaching the problem differently than traditional machine learning methods. Since they do not require pre-processed features, DNNs do not “impose our prior beliefs upon which derived photometric properties” are the most useful. They instead solve the problem agnostically, using the entire raw dataset and learning automatically what the most important features are.
While this sort of philosophy can streamline the tasks of an astronomer at the telescope, a 100,000x slower runtime is a major barrier towards seeing Deep Neural Networks becoming an every-day part of the data analysis pipeline. Perhaps as computing power continues to improve, it may eventually become feasible to implement Deep Neural Networks like the one above to entirely automate the analysis process.
Author
Hey Ben!
Thanks for the bite. Did the authors use parallelization techniques for the DNN implementation? (I couldn’t figure it out from the original paper)