Title: An automatic taxonomy of galaxy morphology using unsupervised machine learning
Authors: Alex Hocking, James E. Geach, Yi Sun, Neil Davey
First Author’s Institution: University of Hertfordshire, UK
Status: Accepted to MNRAS, open access on arXiv
Too much of a good thing?
In 2007, astronomers realized that they had a bit of a problem. The Sloan Digital Sky Survey had observed over a quarter of the sky, obtaining images of a million galaxies. This enormous dataset showed immense promise, especially in helping scientists understand the incredible diversity of galaxy populations… except for the fact that the galaxies first needed to be classified into different morphologies (e.g., spiral vs elliptical galaxies).
A million images were far more than any single scientist, or even a team of scientists, could hope to classify. Even the legendary Annie Jump Cannon classified fewer stellar spectra over the course of her entire career. And unfortunately, computers are pretty terrible at complex tasks like image recognition (here’s a good example), so technology couldn’t help.
Thus the Galaxy Zoo project was born. Perhaps the best-known online citizen science project to date, Galaxy Zoo attempted to fight numbers with numbers by asking members of the public to classify galaxy images. Fortunately, lots of people think space is really cool, so it worked! The original Galaxy Zoo project received over 60 million morphological classifications, and the scientific team made some amazing discoveries (including, but not limited to, the discovery of Green Pea galaxies and the identification of an ionized gas cloud called Hanny’s Voorwerp).
Sadly, the power of citizen science will probably not withstand the sheer amount of data that’s expected to pour in from upcoming surveys. The Large Synoptic Survey Telescope, for example, is projected to obtain 15 terabytes of data every night–that’s more than the Hubble Space Telescope obtains in a single year.
I, machine learning
In the face of such an unrelenting flow of data, we must turn to “big data” computational techniques like machine learning. We’ve covered machine learning here on Astrobites plenty of times before (see here, here, here, here, and here for examples). Although the astronomical applications described in these previous Astrobites vary widely, all of them are based on a method called “supervised machine learning.” This technique uses a training set–a set of data that’s already been classified–to “teach” the computer how to classify data in the future.
This works well, but it has some limitations. For one thing, because the computer is trained on already-classified data, it doesn’t know what to do when faced with new classes of data. Also, the training set must be classified, which is in itself time-consuming.
Is there a way to fully automate galaxy morphology, without requiring any sort of human input? The authors of today’s paper, headed by a computer scientist, present such an “unsupervised machine learning” method that identifies and classifies galaxies from survey images.
Today’s paper
So how does this method work? We won’t get into the nitty-gritty, but here’s the basic gist.
This method is patch-based, which means it doesn’t process whole images of galaxies, but rather small overlapping patches of images. It then relies on a combination of three different algorithms. Two are algorithms based on graph theory: the first algorithm (Growing Neural Gas) creates a simplified representation of the dataset, while the second (Hierarchical Clustering) identifies different types of patches based on their colors and power spectra. Finally, an image processing algorithm (Connected Components Labeling) is used to identify galaxies.
The first time this method is run, the Hierarchical Clustering algorithm is run again to “train” the computer to identify different classes of galaxies based on the kinds of patches in each galaxy (note that no human input is required for this training). After that, galaxies in future images are automatically sorted into these classes.

Figure 1. Galaxy cluster MACS0416.1-2403 from the Hubble Frontier Fields. Figure 4 from paper.
The authors first train their method on Abell 2744, a galaxy cluster from the Hubble Frontier Fields with pretty distinct populations of red elliptical galaxies and blue late-type galaxies. Then they test it on MACS0416.1-2403, another cluster from the Frontier Fields (Figure 1). They find that their method successfully distinguishes between red ellipticals (Figure 2a) and blue late-types (Figure 2b). In fact, this is quantified in a color-magnitude diagram, which shows that the unsupervised machine learning method does a pretty good job of separating different types of galaxies even without knowing anything about the science behind these galaxy types.
-

- Figure 2a. Examples of elliptical galaxies identified in MACS0416.1-2403 by the algorithm.
-

- Figure 2b. Examples of late-type galaxies identified in MACS0416.1-2403 by the algorithm.
-
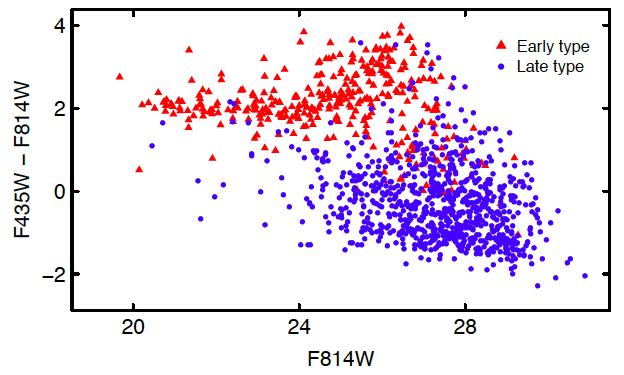
- Figure 2c. Color-magnitude diagram of galaxies identified in MACS0416.1-2403; colors correspond to different classifications.
Finally, to put their method to an even more stringent test, the authors run the algorithm on an image from a different survey: the Hubble CANDELS program (at a recent AAS meeting, we learned why the acronym isn’t spelled “CANDLES”!). Not only did the unsupervised machine learning algorithm again successfully distinguish distinct types of galaxies, its results also agreed well with the human classifications from the Galaxy Zoo program! It was even able to identify rarer types of objects, such as potential gravitational lens candidates (Figure 3).

Figure 3. The machine learning algorithm identified a known gravitational lens (bottom image) and two potential lensing candidates (top images).
This paper shows that fully-automated computational techniques like unsupervised machine learning are starting to become a real option for astronomers. This data-driven approach is especially exciting with the advent of new data-rich surveys–who knows what cool science this technology might help us uncover?
Author
Trackbacks/Pingbacks