Title: Knowledge transfer of Deep Learning for galaxy morphology from one survey to another
Authors: H. Domínguez Sánchez, M. Huertas-Company, M. Bernardi, et al.
First Author’s Institution: Department of Physics and Astronomy, University of Pennsylvania, Philadelphia, PA 19104, USA
Status: arXiv eprint, [open access]
Between Gaia, LSST, COSMOS, and several other large surveys, astronomers are drowning in far more data than any human could ever hope to handle. As a result machine learning, a branch of computer science that “teaches” a program to rapidly process data, is a very popular topic here at Astrobites. One area of research that previously turned to creative approaches in data analysis–from machine learning to crowdsourcing–is galaxy morphology: what shapes are the hundreds of billions observed galaxies? The authors of today’s paper recently released a massive catalog of galaxy morphologies determined by a deep learning algorithm. In the companion paper discussed here, the authors also explore whether the algorithm can be applied to the data from an entirely different survey.
What is deep learning?
Deep learning is a subfield of machine learning, which is itself a subfield of artificial intelligence. Its signature characteristic is the use of “artificial neural networks” (ANNs). ANNs are developed by exposing the code to a large number of examples of something you want to detect (e.g. a car braking in front of you, a particular word, a sunspot, etc.) so that the code can “learn” from the examples which patterns predict the feature. Each ANN might search for a specific feature, such as the color or the shape of an object. Creating layers of ANNs passing each other their outputs gives the “depth” in deep learning. The results of each layer indicate the probability that the data include the characteristic of interest.
ANNs’ function through pattern recognition. As a result, deep learning algorithms benefit from a massive advantage over other algorithms: ANNs learn from examples, so programmers do not need to mathematically describe the salient features. Unfortunately, as a result ANNs require large numbers of examples to achieve high performance. Sifting through massive data sets to find a comprehensive number of examples to give to the code is cumbersome work, and it can defeat the entire purpose of trying to develop faster algorithms.
Deep learning across different surveys
The authors of today’s paper developed a deep learning algorithm to classify galaxy morphologies in the 7th data release from the Sloan Digital Sky Survey (DR7-SDSS). By training the algorithm with 5000 galaxy morphologies from past work the authors classified approximately 670,000 additional galaxies. While the authors already achieved an extraordinary accomplishment with this catalog, they sought to extend the uses of the algorithm further.

Figure 1. Galaxies imaged by both DR7-SSDS (left panels) and DES (right panels). In the right panels, the redshift is given as z and 1/5th the angular size is given as Re. Figure 1 in the paper.
Enter the Dark Energy Survey (DES). Using a 4-meter telescope the survey will map ~ 300 million galaxies over five years. Humans cannot possibly analyze that much data themselves, so the development of algorithms to rapidly process the data is an invaluable goal. As shown in Figure 1, DES observations of galaxies resemble DR7-SSDS images, but they are not an exact match. These changes, caused by differences in the instruments, may not seem significant to the human eye, but for an algorithm optimized to match patterns the differences become huge. Today’s paper explores whether the algorithm trained by the SDSS survey still effectively classifies DES galaxies despite these differences, and, if not, does the algorithm at least benefit from previous training?
The deep learning algorithm was applied to 4,938 previously classified DES galaxies. After the initial test, the algorithm received additional training with 300-500 DES galaxies before repeating the test. As part of the testing process the algorithm determined the probability of three statements being true:
- The galaxy has a disk or other significant feature.
- The galaxy is being seen edge-on.
- The galaxy has a bar signature.
By setting a probability threshold (e.g. we claim the galaxy has a disk if the algorithm predicts a 70% chance or greater that it does), some number of true positives and false positives emerge. Ideally, the true positive rate (TPR) increases much more rapidly with an increasing probability threshold than the false positive rate (FPR). A perfect algorithm produces only true positives and no false negatives, giving TPR = 1 and FPR = 0, at some probability threshold.
Results
As shown in Figure 2, the algorithm at first struggled with the DES galaxies in comparison to its effectiveness with the DR7-SDSS data. Training the algorithm with a small sample of DES galaxies before the test produced dramatic performance improvements. While the algorithm almost always struggled with identifying barred galaxies, the very small number of barred galaxies in the data restricted its capabilities. Only 103 galaxies were confidently identified as having a bar in the DES galaxies, and after the training algorithm only 9 were available for testing.
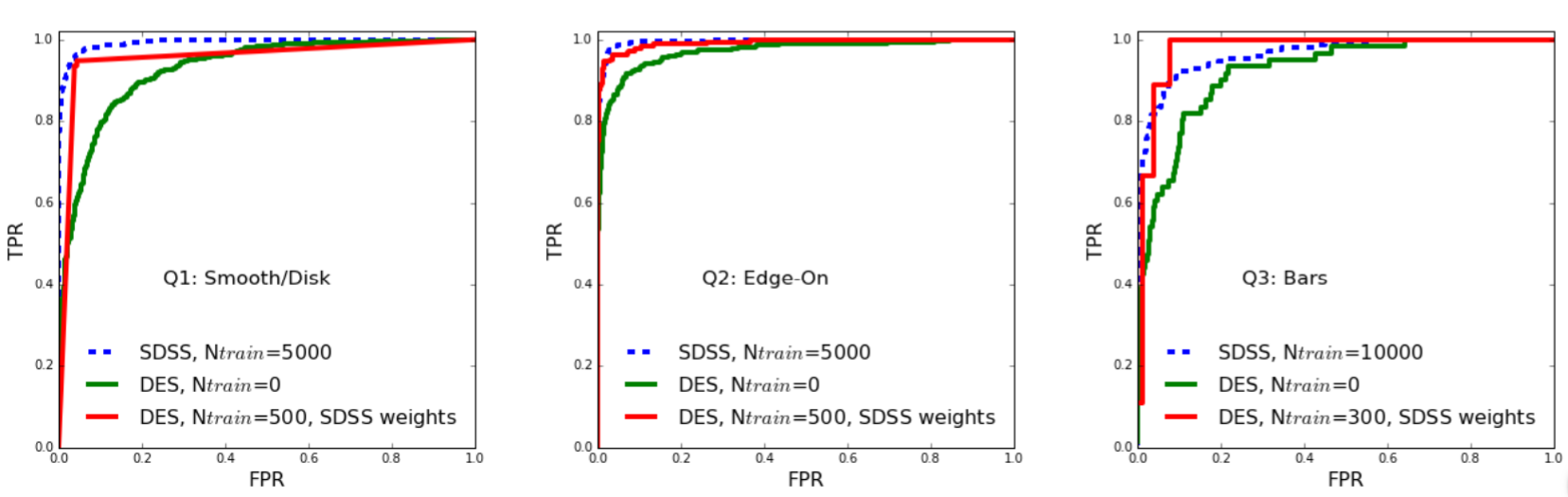
The receiver operating characteristic (ROC) curve for the three questions. As the probability threshold is increased, there are fewer false negatives so the TPR increases. However, the FPR rate also increases. The best algorithm will therefore achieve a high TPR without also generating a high FPR. Figure 2 in the paper.
Achieving an effective algorithm with only 500 training galaxies is a tremendous improvement. At a human level, 500 galaxies are far easier to classify by eye than 5000, the number required for the initial SDSS data. As the authors note, they accomplished a full order of magnitude improvement. Therefore, continuing to develop deep learning algorithms will likely enable the rapid adaptation of powerful algorithms for massive data sets. While this paper was intended solely as a proof of concept, the authors call for future work to begin applying this deep learning transfer technique to build morphology catalogs and explore if similar approaches can work for characterizing galaxies at different redshifts.
Author