Authors: Fergal Mullally, Susan E. Thompson, Jefferey L. Coughlin, Christopher J. Burke & Jason F. Rowe
First Author’s Institution: SETI Institute, Mountain View, CA
Status: Accepted to the Astronomical Journal, open access
Recent announcements of large batches of exoplanets discovered using the Kepler space telescope have relied on statistical methods. Rather than relying on expensive imaging and spectroscopic follow up of candidate objects these studies rely on a large number of tests meant to weed out false positives. These false positive signals could be astrophysical in nature (e.g. a background eclipsing binary) or due to noise sources inside the camera. Today’s paper calls into question the statistical confidence of these methods when used on low signal to noise ratio (SNR) candidates with long periods and specifically disputes the 99.97% confidence of Kepler-452b.
Before we dig into the results it is useful to define a few terms. First, the completeness of a vetting method is the fraction of real planets correctly identified. Similarly, the effectiveness refers to the fraction of false positives correctly identified. Finally the number we are after is the reliability of a method, or the fraction of claimed detections which are real (and not false positives).
The authors of this paper use two lines of reasoning to argue that purely statistical validation of long-period (200-500 days), low SNR (<10) planets is much less certain than previously thought. First, they argue that the number of false positives in this regime drastically outnumbers the number of true planet signals. Specifically, there is a large build up of false positive signals with periods around 370 days caused by noise characteristics changing with the period of the Kepler spacecraft (period of 372.6 days). This means that any method for validating such candidates must be extremely effective at identifying such false positives.
The second argument the authors make is that it is extremely difficult to identify false positives effectively without also reducing the completeness. To test the effectiveness of a method you must first produce a set of data which you know do not contain transits but also exhibit the same noise properties. One way to do this is to invert real light curves. This turns real transits, which dim the light of the star, into brightness increases which are difficult to produce astrophysically. The pipeline then looks for candidate transits which you know are caused by noise (since these would have been brightness increases in the original data). Previous work by another team found that Robovetter (one of the main software packages used to verify candidate transits) has an effectiveness of 98.3% (almost all false positives are correctly identified and only 1.7% are misidentified as real transits). Figure 1 shows just how difficult this is. Can you identify which set of transits are Kepler-452b and which are inverted light curves (fake transits caused by noise)?
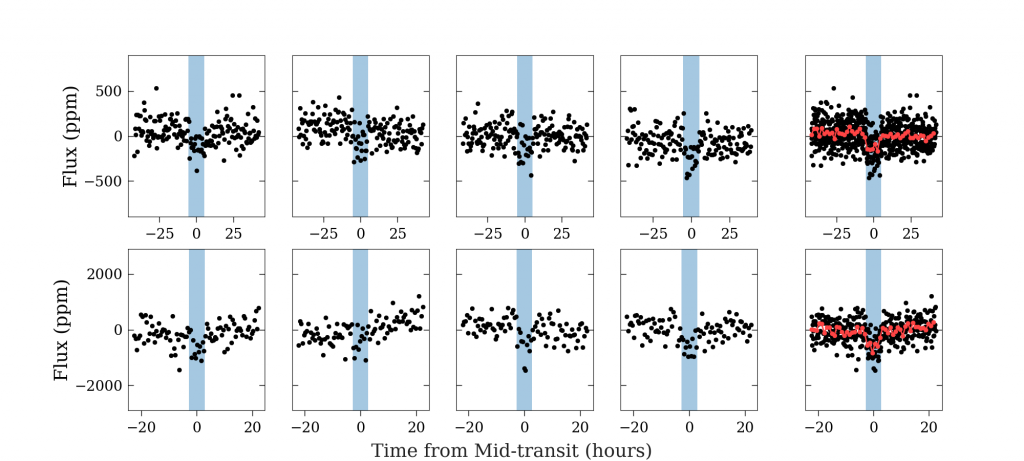
Figure 1: Top and bottom rows show a different candidate transit signal, highlighted in blue. The four panels on the left are each individual transits while the rightmost panel is the stacked (folded) light curve (red points show binned data). Can you tell which of these light curves is Kepler-452b and which is simulated fake data? (the answer is at the end of the post). Figure 1 in the paper.
To put some numbers to these arguments, the authors examined how well Robovetter performed on a sample of long-period, low SNR real transits (not inverted light curves). Robovetter examined a sample of 3341 candidate transits and found 67 planet candidates. Using the previously known effectiveness of Robovetter of 98.3% (discussed above), this means that 56 false positives were misidentified as real signals (If the 3341-67=3274 false positive signals are only 98.3% then 56 false positive signals were incorrectly identified as real). This produces an abysmal 16% reliability for this class of candidate transit! Due to the large number of false positive signals in this regime even a 98.3% effectiveness is not good enough. Using a higher threshold for what Robovetter considers a candidate only improves this reliability to 92%, still far shy of the 99% usually required to claim statistical confirmation.
To sum up, statistical confirmation of long-period, low SNR candidates should be taken with a grain of salt. These confirmations are still useful in large scale studies, as long as the lower reliability of candidates in this regime is taken into account. However, the reliability of these methods is too low to confirm individual systems without followup observations and the 99% confidence validation of Kepler-452b is likely closer to 90%.
(Answer to the caption of Figure 1: Top row is Kepler-452b, bottom row is an inverted light curve.)
Author
Trackbacks/Pingbacks