Paper title: Chemical tagging can work — Identification of stellar phase-space structures purely by chemical-abundance similarity
Authors: David W. Hogg, Andrew R. Casey, Melissa Ness, Hans-Walter Rix and Daniel Foreman-Mackey
First author’s institutions: New York University and Max-Planck-Institut für Astronomie
Status: Submitted to The Astrophysical Journal

See that star? Could it be a sibling of the Sun? Credit: ESO/B. Tafreshi (twanight.org)
When a dense cloud of cold gas and dust collapses, then we have the birth of stars. They stick together for some time, as stellar clusters, but these eventually break up over the ages, and the sibling stars are scattered from each other. The best example of a lonely star we have is our good and old Sun. Luckily, astronomers have thought of a clever way to trace stellar siblings in the Milky Way. In the future, we may even be looking for the Sun’s sister stars using our telescopes. Not only that, but if we can trace the history of these stars, we can better understand how our Galaxy evolved.
Introducing: chemical tagging
For stars that are born in the same natal cloud, it is not unreasonable to assume that they have the same (or at least very close) chemical compositions, which astronomers measure by the quantities called chemical abundances. Moreover, for stars with a mass similar to the Sun, these abundances keep practically unchanged in the stellar surfaces for most of their lives. So astronomers had the thought: if we looked at the chemical composition in the stars’ surfaces, would we be able to identify stellar siblings just with that information? This is the question today’s paper tries to answer.
The process of looking for stellar siblings using the surface composition of stars became known as chemical tagging. What the authors of today’s paper did was a proof of concept: to test if it was possible to identify stellar clusters (which we know to definitely be sibling stars) using chemical tagging. The idea is that if works for clusters, it will also work for siblings scattered from each other. To do that, they used The Cannon, a machine learning program capable of creating stellar models using only the spectra of stars. The data to be fed to The Cannon was obtained in the APOGEE survey.
Sounds crazy, but it works

In this plot, we have abundances of different elements on all axes. We can infer that stars that appear together, forming structures, in plots for all elements were probably formed together (colored symbols). The light grey symbols are the other stars of the survey who are unrelated to the colored ones.
With the spectra of the stars and their respective stellar models, they calculated the chemical composition in the surface of the stars (16 elements in total) for almost 100,000 of them. That’s a lot of parameters and stars to look for any kind of structure in the abundances data, so they had to resort to an algorithm that automatically looks for these structures (and a very straightforward one at that, too). Nevertheless, what they found is that, only by looking at the similarities in chemical abundances, they could identify various stellar clusters, such as M15, M92 and M107, the Saggitarius spheroidal dwarf galaxy, and even a collection of old stars that do not seem to be bound to a particular cluster.
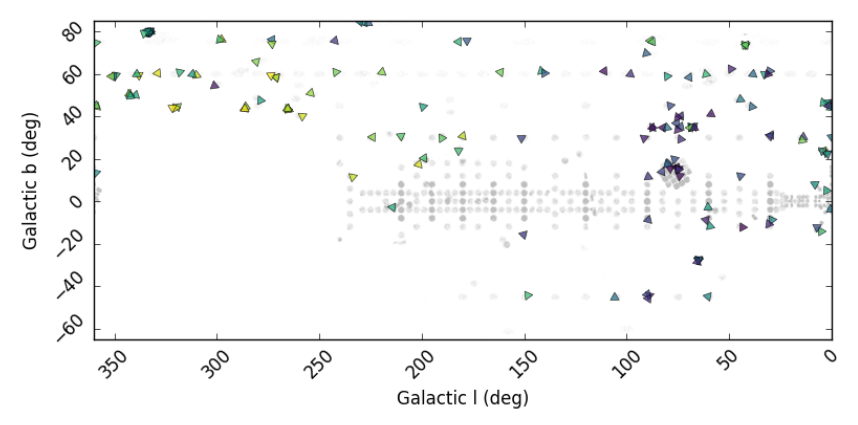
Position of the stars in galactic coordinates. They could identify that these stars (the colored symbols), which are scattered through the disk of the Milky way could have been born together! The light grey dots are, again, stars unrelated to the colored ones who were observed in the survey.
In the past, chemical tagging was criticized for being too difficult to perform and people questioned its reliability. Ultimately, what the authors prove with this study is that identifying stellar siblings just by looking at their surface chemical composition does work, and it doesn’t even need a sophisticated algorithm to produce reliable results. What we need, actually, is precision in abundances, which was made possible with The Cannon. All this means that we are off to a great start in understanding even better how our Galaxy evolved and its star formation history.
Author
Trackbacks/Pingbacks