Article: Discovering the Unexpected in Astronomical Survey Data
Author: Ray P Norris
First author’s institution: Western Sydney University, Australia
Major advances in astronomy usually follow advances in telescope technology that allow us to observe the universe in different wavelengths or at greater sensitivities. These breakthroughs may result from observations in which a model or hypothesis is being tested, or they may occur unexpectedly due to the fact that we are probing previously unexplored regimes. These discoveries may be new types of objects (pulsars, quasars) that are initially identified as anomalous, or phenomena that are apparent when we find discrepancies between observation and theory (ex. the accelerating expansion of the universe).
In this paper, the author presents a case for how we should approach data analysis in future telescope surveys. When scientists obtain observational results that are unexpected, there is a tendency to assume that the deviations from normalcy are due to some sort of error or oversight. However, the majority of the major astronomical breakthroughs in the past decade were the result of serendipitous discoveries, rather than intentional hypothesis testing. For example, out of the 10 greatest discoveries made by the Hubble Space Telescope (as recognized by National Geographic), only one of them was listed in its initial science goals. One of the Hubble Space Telescope’s unexpected discoveries was the existence of dark energy, but this unexpected find led to a Nobel Prize.
Currently, there are multiple next-generation survey telescopes being planned or constructed. While we expect these projects to expand our astronomical knowledge by achieving most of their stated science goals, the unexpected discoveries they make may potentially be the most important ones. One of these projects is the Evolutionary Map of the Universe (EMU), which plans to survey 75% of the sky in the radio and detect up to 70 million sources (compared to the roughly ~2.5 million known radio sources so far). Fig 1. shows the limiting sensitivities and sky coverage of current and planned radio surveys. The large area of parameter space that we haven’t explored yet suggests that many more discoveries are yet to come.
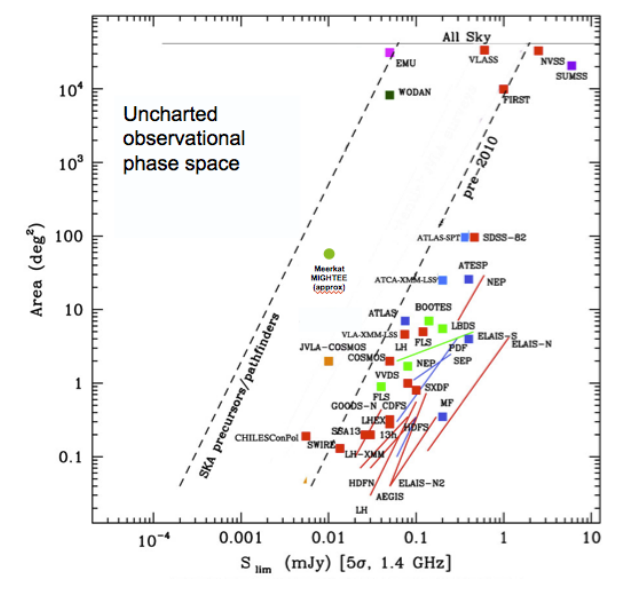
Fig. 1: Diagram showing the parameter space covered by existing and planned deep radio surveys. The dashed diagonal lines show the limits in area and flux sensitivity spanned by these projects. A large number of unexpected discoveries have already been made by these telescopes, and it is fair to assume that there are more discoveries to be made if we probe the unexplored region of the parameter space.
Advances in instrumentation and data processing allow astronomers to collect and process huge amounts of data faster than ever. On the flip side, extremely large data sets can make it more difficult to make serendipitous discoveries manually, since it is impractical for humans to look through everything manually to see anything unusual that we may have overlooked. Most data processing and cataloging is automatically done by computers nowadays, but any attempt to detect unexpected effects is likely going to pick up a lot of meaningless artifacts and erroneous signals. How then, can we prepare ourselves to search for the unexpected?
The author proposes a general method for identifying any unexpected objects in the EMU project that may represent potentially new discoveries. Fig. 2 shows a flowchart of this process, which can be easily generalized to other telescope projects as well. After an observation is made, the data are processed via an automated pipeline that classifies individual objects, and then unfamiliar and unusual objects are automatically identified using machine learning techniques (via the aptly named Widefield ouTlier Finder, or WTF). Allowing a computer to automatically select anomalous objects under the pretense of finding previously undiscovered objects may lead to a large number of false positives, so these objects are then classified and analyzed by citizen scientists through mass public participation (an approach similar to Galaxy Zoo). Objects flagged by citizen scientists to be of interest are then further analyzed by the project scientists themselves. This combination of automation and manual inspection makes it feasible for us to search for proverbial needles in massive haystacks of astronomical data.
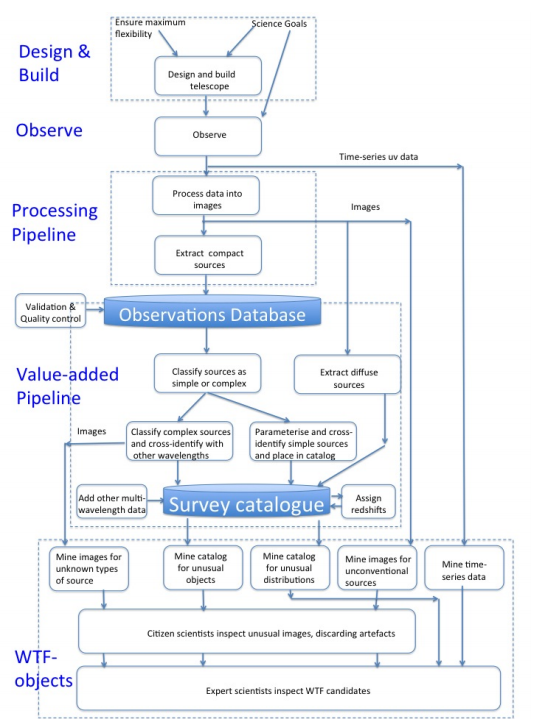
Fig. 2: Flowchart showing the steps involved in discovering unexpected objects in the EMU. The bottom most dashed box indicates the interface between automated processing and manual classification by humans.
As Louis Pasteur once quipped, “Chance favors the prepared mind.” While we certainly can’t predict with any certainty what we may discover among the ‘unknown unknowns’ of future telescope surveys, through a combination of computational methods and citizen science we can be as prepared as possible.
Author