Authors: Stephen Durkan, Markus Janson, Joseph C. Carson
First Author’s Institution: Queen’s University Belfast, UK
Status: Accepted to ApJ
Direct Imaging is kind of the “new kid on the block” for exoplanet detection – although planets were first directly imaged 8 years ago, in 2008, even today only ~10 of the ~2000 known exoplanets have been directly imaged. You need the biggest, fanciest new instruments, like SPHERE and GPI to image new planets . . .
Or, you could go back and reanalyse Spitzer data from 2003.
That’s what the authors of today’s paper have tried to do: the idea is that the post-processing techniques for data analysis have got so much better over the last 13 years, that new detections can be be made even in old data. In fact, there is similar work going on looking at archival Hubble data from the 90s.
Spitzer data are particularly interesting, since they open up a new region in which to look for planets – wider separation planets can be found with Spitzer than with ground based telescopes.
Since Spitzer is in space and firing things into orbit is hard, it’s much smaller than lots of ground-based telescopes. This means the resolution is lower, and planets close to their host stars are impossible to detect. However, Spitzer is in space, meaning that atmospheric distortions aren’t a problem. On the ground, the atmosphere blurs out any light passing through it, and is generally a huge pain if you’re into observational astrometry. Very clever people invented very clever adaptive optics systems for dealing with the atmosphere – but these need a bright light in the sky to model the atmosphere and use it to correct the atmospheric distortions. This restricts the best quality observations to within a fraction of a degree of a bright target. Happily, most planets are orbiting stars, which are bright. However, if you look too far from the bright star, the adaptive optics stops working so well. None of this is a problem for Spitzer, which is in space, and so can actually reach wider separations than ground-based telescopes, without worrying about the pesky atmosphere.
For this planet search, the authors focus on the region between 100AU (roughly twice Pluto’s orbit) and 1000AU (half way to the Oort cloud) – Planet IX, if it is real, lies somewhere in the middle of this region. They use a total of 121 stars, from two archival Spitzer programs taken during 2003 and 2004. They’re mostly very close stars, and are fairly similar to the Sun.
Old Data, New Planets?
I mentioned earlier that data reduction of post-processing of images has improved dramatically in the last decade: one big new tool at our disposal is something called PCA, or Principal Component Analysis. The maths of this technique was figured out by Karl Pearson back in 1901, but it wasn’t applied to Exoplanet Imaging till as recently as 2012.

Figure 1: The top image shows the standard output of the Spitzer data processing pipeline. The bottom one shows the same star, after the team’s reanalysis: far more of the stellar light has been removed within the central grey box, by using a library of images to understand and then subtract the noise pattern. In this image, several planetary candidates are revealed above the star.
The objective is to remove as much light from the star as possible, and only leave the planetary signal in our images. It works like this: first, you build a library of ‘reference images’ that characterise the noise (both random noise and leaking starlight) in your image, that you’d like to remove. These references could be a whole series of images of the same star are taken at different orientations – the noise is fairly constant between the images, but the planet moves between each one, so it doesn’t get subtracted out.
Then, you test how similar each library star is to your current target, and build a custom reference image that’s as similar as possible to your target. This reference image is split into its ‘principle components’ – the set of simple patterns that add up to create your image. These components are subtracted one at a time to find the best noise removal solution (we’re balancing ‘remove all the noise’ with ‘don’t remove any of the planet signal’).
For this to work, you want your reference images to be as similar as possible to each other – ideally, photographs of the same star taken on the same night. The idea of turning your telescope to create the reference images is known as Angular Differential Imaging, and was first published in 2006. In other words, it was published three years after the Spitzer data was taken. So observing sequences weren’t set up like this, and ADI wasn’t an option with this data.
As such, for this work, all the targets act as reference images for all the other targets. That makes this survey an interesting test of PCA in very non-optimal conditions – as you can imagine, the noise in each image varies a lot more over the course of a year than in an hour, especially if each image is of a different star.
And the algorithm passes with flying colors! The authors put a lot of care into matching the images to each other very carefully, and then let PCA work its magic. The final results are like those in figure 1.
So, what’s out there?
Well, nothing. 34 candidates are initially found, but follow-up studies show that they are all either distant background stars, or data quirks – bad pixels on the chip, for example.
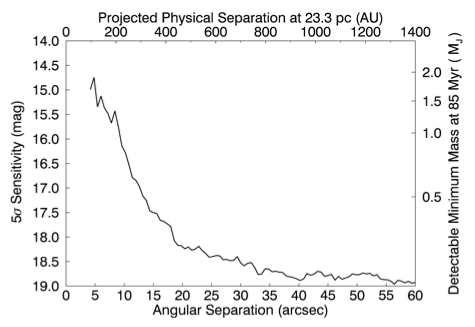
Figure 2: This plot show the sensitivity of the survey. The bottom axis shows the angle from the star in arcseconds, while the top axis shows this converted into AU (the distance between the Earth and the Sun) for the average distance of target stars. Bear in mind that Pluto orbits at ~40AU! The left and right axes show planet detection limits for brightness (in magnitudes) and mass (in multiples of Jupiter mass) respectively.
It’s still an interesting result though, because no-one has really tested planet frequency this far out before. In the final part of the paper, the authors simulate that we would be able to detect 42% of planets that had such wide orbits. The undetectable 58% would be too low in mass, or lined up badly – hidden behind the host, for example.
The number of stars observed, the detection fraction listed above, and the survey non-detections lead the authors to calculate that less than 9% of stars host super wide separation, massive planets. Lots of work is going on currently to understand the formation of planetary systems – and this paper adds one more constraint: a successful planetary formation theory would have to predict this super-wide lack of planets. We don’t yet understand the formation of planets, but we’re certainly inching closer!
Author
Trackbacks/Pingbacks