Title: Research Debt
Authors: Chris Olah and Shan Carter
First author’s institution: Google Brain
Status: Published in Distill (2017) [open access]
Let’s start with a short, back-of-the-envelope (back-of-the-blog-post?) calculation.
- Roughly 50 new astronomy papers appear on the arXiv every day.
- A typical paper is 10 pages long, with (conservatively) 500 words per page.
- The average human reads 250 words per minute.
So if you wanted to keep up, in detail, with every new development in astronomy, you’d have to spend about 17 hours per day reading. Perfect! Just enough time for a restful 7 hours of sleep before hitting the arXiv anew. (Astrobites will save you a little time, but even we can only summarize about one paper per day!)
There’s only one problem with this otherwise ideal routine: The number of papers published every year is growing.
Check out the results of the most general possible astronomical literature search I could think of—every paper published between 1950 and 2017 with the word “star” in its abstract.
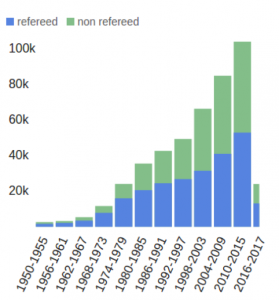
Figure 1: The number of papers published in each 5-year interval with the word “star” in their abstract. Wow, we sure did discover a lot of stars!
Try it yourself! Sub out “star” in the search bar for any other general astronomical thing—“galaxy,” “cosmology,” “planet,” “black hole”—and you’ll see the same trend. Papers upon papers upon papers. If you try to keep up in the face of this tsunami of new astronomy, your blissful 7 hours of sleep will dwindle quickly. By the time we hit 72 arXiv postings per day, you’ll be reading continuously.
Clearly, a lot of astronomy is being done. But is so much astronomy good for astronomy?
The Debt
No astronomer, of course, has 17 hours per day to spend reading papers. Most people limit themselves to one or two subject areas relevant to their own research and, of the papers in those subject areas, read only a small subset in full. That cuts the reading burden down to, say, 5 abstracts per day, or 1000 words.
We save enormous amounts of time this way, but we lose any hope of maintaining an up-to-date view of astronomy overall. I often wonder how much redundant astronomy is done as a result—researchers in different sub-fields toiling away in parallel to solve analogous problems.
The distance between the small heap of astronomy we understand and the mountain of astronomy out there in the literature is called research debt. The debt is most obvious when I couch it in terms of the sheer number of published papers vs. the small handful we could ever hope to read carefully. But research debt creeps insidiously into even the papers we do have time to digest. A muddled explanation of an idea? Research debt. An introduction which fails to clearly relate a new result to earlier work on the topic? Research debt. A poor choice of metaphor, vocabulary, or notation, introduced in one paper and echoed uncritically thereafter? Debt, debt, and more debt.
We can also think about research debt as a great burden placed on the readers of astronomy papers. A single idea, explained poorly, may cost every individual reader several minutes to puzzle through. All that time adds up, and it might have been saved at the start had the author spent a little more time polishing the explanation. (Think, for example, of the astronomical magnitude scale, invented in ancient Greece and totally backwards by any modern standard. How many thousands of hours of mild confusion to outright frustration might have been avoided if this system were sensibly revised?)
Paying it down
Right now, there exists little incentive for spending time and effort to eliminate the research debt. Certainly, individual researchers who devise good and intuitive explanations for their work are likely to benefit in small ways—better-attended talks, better-cited papers. But poor explanations get cited, too, and unhappily, deliberately making your work seem more complicated may not hurt you.
And, of course, not adding to the research debt is not the same as reducing the research debt. That brings us to today’s paper and, indeed, today’s journal, which is itself new. Chris Olah, Shaun Carter, and the Distill editorial team are hoping to solve the problem of research debt in machine learning, a subset of computer science. They want to incentivize what they call research distillation—taking the existing mountain of literature, refining it down to the essential ideas, and clearly explaining and contextualizing those ideas. Plenty of people are paid to do research, they argue, but no one is paid to distill it, and science suffers.
Part of their plan is the journal Distill itself, which will accept results in forms beyond the traditional research paper. (Why, they argue, does every new result, however small, need to be ensconced in a dense, technical, 10-page document?) Another part is a $10,000 prize for an “outstanding explanation of machine learning.” A third part, perhaps the most generally applicable to astronomy, is a suite of tools for making interactive documents, including research papers.
If I had to distill my own Astrobite, I’d say this: remember, astronomers, that explaining is teaching, and teaching is work. But time spent explaining things well is invested, not wasted, because it makes astronomy healthier. If we don’t want the field splitting up into exoplanetary science, and cosmology, and particle astrophysics, we’d better get distilling.
Featured image via Wikimedia Commons.
{kind=link}
Author
We amateurs are counting on you “faster than the average reader” Astrobiters to distill the entire universe for us. .What you have done to date is fabulous, do not give up, or we might.