Title: The impact of human expert visual inspection on the discovery of strong gravitational lenses
Authors: Karina Rojas, Thomas E. Collett, Daniel Ballard, Mark R. Magee, Simon Birrer, Elizabeth Buckley-Geer, James H. H. Chan, Benjamin Clément, José M. Diego, Fabrizio Gentile, Jimena González, Rémy Joseph, Jorge Mastache, Stefan Schuldt, Crescenzo Tortora, Tomás Verdugo, Aprajita Verma, Tansu Daylan, Martin Millon, Neal Jackson, Simon Dye, Alejandra Melo, Guillaume Mahler, Ricardo L. C. Ogando, Frédéric Courbin, Alexander Fritz, Aniruddh Herle, Javier A. Acevedo Barroso, Raoul Cañameras, Claude Cornen, Birendra Dhanasingham, Karl Glazebrook, Michael N. Martinez, Dan Ryczanowski, Elodie Savary, Filipe Góis-Silva, L. Arturo Ureña-López, Matthew P. Wiesner, Joshua Wilde, Gabriel Valim Calçada, Rémi Cabanac, Yue Pan, Isaac Sierra, Giulia Despali, Micaele V. Cavalcante-Gomes, Christine Macmillan, Jacob Maresca, Aleksandra Grudskaia, Jackson H. O’Donnell, Eric Paic, Anna Niemiec, Lucia F. de la Bella, Jane Bromley, Devon M. Williams
First Author’s Institution: Institute of Cosmology and Gravitation, University of Portsmouth, Burnaby Rd, Portsmouth PO1 3FX, UK.
Status: Available on the ArXiv
How do you think you would fare against a computer in a game of astrophysical “I-spy”? Today’s article explores the ability of human experts to identify gravitational lenses in a set of nearly 1500 images, in an attempt to better grasp the role human beings might play in the increasingly computer-dominated industry of lensing detection.
Real Humans, Artificial Intelligence
In an era where terms like “artificial intelligence” and “machine learning” are thrown around in everyday conversations, it can sometimes be hard to appreciate that human labor is still essential in enabling such technologies to perform as desired. For example, to train a neural network, human beings often have to act as teachers to help the network better understand when it succeeds and when it fails at its given task. In fact, if you’ve ever verified your identity on a website by identifying objects in images, for example through Google’s ReCAPTCHA service, you’ve likely participated in such a training activity yourself, without even knowing it.
This idea of human intervention is extremely relevant when it comes to using machine learning techniques in astrophysics and astronomy. While large-scale surveys enabled by modern telescopes provide useful data and imagery, relying on computers alone to identify particular features of interest in the data may miss certain things a human eye would catch, or produce unhelpful false-positive detections of some object of interest. As such, in the final stages of analysis, it is still useful for human beings to step in and check the work of their A.I. counterparts.

The detection of gravitational lenses is no exception. Such lenses are the result of extremely massive or compact objects warping spacetime, and are a key prediction of general relativity. This warping can cause distortions in the appearance of background objects, but like a traditional optical lens you would find in a pair of glasses, it can also focus or even magnify light from objects such that we see them more clearly here on Earth. This makes gravitational lenses great tools for studying faint or incredibly distant objects otherwise invisible to us, as well as for studying dark matter, testing cosmological models, and exploring lots of other astrophysical questions. In extreme cases, gravitational lenses can stretch the appearance of background objects into dramatic arcs known as Einstein rings, or produce distinctive double-images. Traditionally, searches for these lenses have been conducted via human inspection, often with teams of scientists visually combing through images. Now that computers are taking over much of this identification process, humans are increasingly playing the role of trainers and work-checkers, as computer models still suffer from large false-positive rates due to the inherent rarity of identifiable gravitational lenses. But human beings have their own biases, so understanding which images humans can or cannot reliably identify is important to making sense of their effects on the final stage of image filtering.
Relativistic ReCAPTCHA
In today’s paper, the authors set up a sort of relativistic-ReCAPTCHA: a study to determine just how well “human experts” (people with some exposure to astrophysics, from master’s students to professors with decades of experience in gravitational lensing) could identify such lenses across hundreds of images. In order to test the participants’ strengths and weaknesses across a variety of lensing scenarios, they were presented with images taken from several different datasets and simulations, containing images with and without lenses. Each image was presented in three different brightness scales (default, blue, and square-root) to allow the best delineation of subtle features. The authors expected that a set of simulated lenses with bright background features would be the easiest for human experts to identify, and that the lenses imaged by ground-based telescopes would be the most difficult to discern.

In order to quantify how well each image was classified and across each category, participants were told to label each image as certainly containing a lens, probably containing a lens, probably not containing a lens, or very unlikely containing a lens. Objects for which a large number of participants claimed certainly had a lens were given aggregate scores closer to 1, whereas objects where a large number of participants decided a lens was unlikely received scores closer to 0. By tracking how the mean score for various objects correlated with parameters such as magnitude, signal-to-noise ratios (SNR), and whether or not there actually was a lens in the image, the research team was able to determine where human experts were more or less reliable.
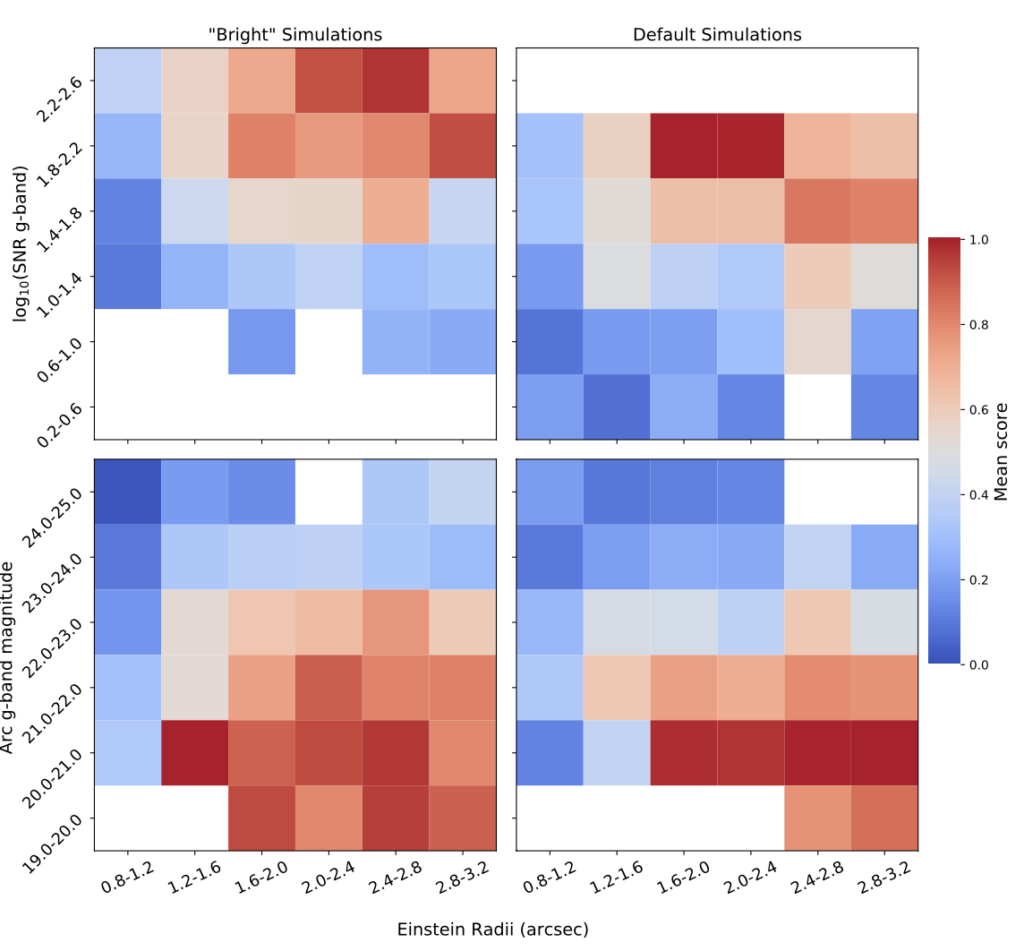
As shown in Figure 3, humans reliably identified images with lenses (i.e. gave high scores) when the radii of the Einstein rings were greater than 1.2 arcseconds and the lensed object was brighter than an astrophysical magnitude of 23 (~4,000 times dimmer than Pluto as seen from Earth). When comparing human expert scoring against the scoring produced by a convolutional neural network (CNN) trained to identify lenses, the researchers found very little correlation, especially in ambiguous imagery (human scores close to 0.5), indicating that the CNN they compared against may be picking out different types of features in the imagery than its human counterparts.
Despite the shortcomings of human experts in detecting small or dim lenses, the researchers found that on the whole the participants reliably classified images. For example, 99% of images labeled “certain lenses” by the participants did indeed contain a lens, and 80% of images labeled “very unlikely to contain a lens” indeed lacked one. The highest ambiguity was when human experts tagged an image as “probably not containing a lens” — images tagged this way were almost evenly split between images with and without lenses. Perhaps surprisingly, the team found that the reliability of scoring was not correlated with academic position, years of experience, or the self-reported confidence of participants. (So if you’re reading this, there’s a good chance you could beat an expert in a game of cosmic “I-spy”)!
Teamwork Makes the Gravitational Lens Identification Dream Work
Despite the human experts being reliable classifiers in aggregate, the study found fairly high variation in scoring between individuals. This is especially problematic when humans are given ambiguous imagery that computers themselves may struggle to classify. Making this problem even worse, the researchers found that when participants were shown an image they had previously classified, they changed their classifications 27% of the time.
To account for some of these effects, it may be preferable to have groups of multiple experts work on classification together. In order to examine how accuracy and reliability of classification changes with group size, the researchers sub-sampled their data, creating 200 virtual “teams” of random sizes and compared their performance. In order to reduce the standard deviation in scoring to below 0.1 on their 0-1 scale, they found teams of 6 or more users were necessary. To achieve a standard deviation below 0.05, teams needed to be composed of 15 or more classifiers, indicating diminishing returns as group size is increased.
As powerful new telescopes and surveying projects expand our capacities to explore the cosmos, our catalogs of potential gravitational lenses are likely to expand dramatically. Despite the ever-increasing abilities of computational methods to pick out candidate lenses from the vast sea of images, humans still play a vital role in confirming their presence and training computer models. And, as is typically the case in astronomy, the best results will likely come from scientists coming together to work as a team.
Astrobite edited by Mark Dodici and Graham Doskoch
Featured image credit: Modified by L. Brown from Rojas et al. 2023